
A team rolls out an LLM feature. The demo looks great. Early tests pass.
A week later, users start noticing something off. The answers are still fluent, but less precise, often slightly inconsistent, sometimes just wrong in ways that are hard to explain.
Nothing is obviously broken, and yet confidence drops.
That’s the kind of failure LLMs introduce: not a crash, but a slow drift in behavior.
This is where LLM evaluation becomes essential. Not as a final check before release, but as a way to understand how a system behaves under real conditions, and how that behavior changes over time.
In this guide, we’ll look at how LLM evaluation works in practice, from evaluation methods and metrics to frameworks and common mistakes, and how teams build a process that keeps LLM performance measurable and under control.
Key Takeaways
- LLM evaluation is about assessing behavior and usefulness, not matching exact outputs.
- A strong evaluation process starts with clear criteria instead of tools or frameworks.
- Real user inputs are far more valuable than synthetic prompts for reliable evaluation.
- LLM-as-a-judge can scale evaluation, but it requires careful setup and oversight.
- Benchmarks are useful for comparison but rarely reflect real application behavior.
- Separating deterministic system checks from LLM evaluation keeps testing practical and focused.
- Production data is essential for uncovering edge cases that do not appear in controlled tests.
- The goal is not perfect outputs, but consistent and acceptable behavior within defined bounds.
What LLM Evaluation Actually Means
The key thing to understand here is that LLM evaluation is not about checking exact outputs. It’s about evaluating whether an LLM performs as expected within a specific application.
In an LLM app, the same input can produce different valid answers. That shifts evaluation from strict comparison to assessing whether the LLM output is useful, correct, and follows instructions.
In reality, LLM evaluation focuses on:
- Answer quality and relevance
- Instruction following
- Use of context (RAG evaluation)
- Output format and structure
- Basic safety behavior
This is not general AI app testing or standalone model evaluation. You are evaluating how a large language model behaves inside an LLM system or LLM app, often as part of a broader workflow or AI agent.
A simple distinction:
- Model evaluation → general LLM performance
- LLM evaluation → performance in your application
Even a small evaluation process — a test dataset and clear evaluation criteria — is enough to move beyond guesswork and start evaluating LLM outputs consistently.
A common takeaway from industry discussions is that testing a handful of prompts gives a false sense of confidence. Outputs may look correct in isolation, but without a dataset and repeatable evaluation, it’s hard to see how the LLM behaves across variation or after changes.
Why Traditional Testing Doesn’t Work for LLM Applications
Traditional testing assumes deterministic behavior. LLMs don’t behave that way.
A large language model can return different outputs for the same input. This makes strict pass/fail testing unreliable when you evaluate an LLM.
The main differences:
- No single correct answer
- Subtle regressions instead of clear failures
- Broader, less predictable input space
At the same time, parts of an LLM system remain testable with standard methods:
- API behavior
- Data flow
- Formatting checks
Effective evaluation combines both — traditional testing for deterministic components and LLM evaluation methods for generated outputs. That combination is what makes LLM testing a separate and necessary discipline.
Is your LLM app ready to see the world?
Let us tell you for sure.

What Happens When You Don’t Evaluate LLMs Properly

An LLM application can appear stable and still produce unreliable results. Without proper LLM evaluation, issues don’t show up as failures — they show up as inconsistency.
The most common outcome is silent degradation. The LLM still works, but its performance shifts over time.
Typical signs of LLM quality decline:
- Answers become less precise or relevant
- Instructions are followed inconsistently
- Output format breaks in edge cases
- Tone or style drifts
Another issue is false confidence. Testing a few prompts is not enough to evaluate an LLM. Without a test dataset, you are only seeing a narrow slice of behavior.
What this leads to:
- Uneven user experience across the same application
- Incorrect LLM output presented as reliable
- Issues discovered only after release
- Growing loss of trust in the LLM system
For a RAG-based LLM, the risks are more specific:
- Ignoring provided context
- Mixing retrieved data incorrectly
- Generating unsupported answers
A recurring pattern from real-world use: teams often notice problems only after users interact with the system at scale. By then, evaluation becomes reactive instead of controlled.
A basic evaluation process — even a small dataset and simple criteria — helps avoid this by making LLM performance visible and comparable over time.
How LLM Evaluation Works in Practice
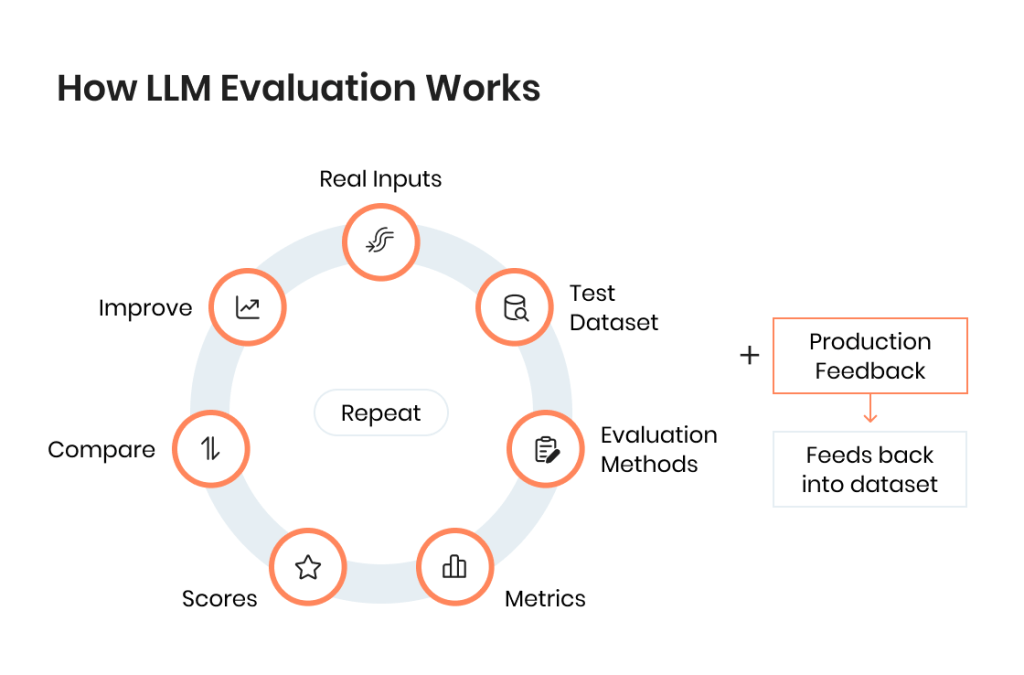
LLM evaluation is not a single method or tool. It’s a structured process used to evaluate LLM outputs consistently across a dataset and over time.
In most LLM applications, evaluation follows the same basic pattern: define what “good” looks like, test against real inputs, and track evaluation results after changes. This applies whether you use a simple setup or a full evaluation framework.
The three building blocks of large language model evaluation
At a practical level, LLM evaluation is built on three components:
- Test dataset — a set of inputs used to evaluate an LLM
- Evaluation criteria — what defines a good or acceptable LLM output
- Evaluation method — how you assess the output (rules, scoring, or review)
Together, they form a simple evaluation system. Even without advanced tools, this structure allows you to evaluate an LLM in a repeatable way.
Without one of these pieces, evaluation becomes unreliable. For example, without a dataset, you cannot compare changes. And without criteria, you cannot assess an LLM consistently.
What makes a good LLM evaluation dataset
A good evaluation dataset reflects how the LLM application is actually used. It should include:
- Teal user queries or realistic inputs
- Common scenarios and edge cases
- Examples where the LLM previously failed
- Variation in phrasing and complexity
One important detail: a test dataset is not static. As you evaluate LLM outputs and discover issues, new cases should be added. This is how evaluation improves over time. The dataset becomes a record of what the LLM handles well and where it still struggles.
In reality, evaluation datasets rarely stay fixed. Teams often expand them over time by adding real failure cases discovered in production, turning the dataset into a record of how the LLM behaves under real conditions.
Deterministic vs. non-deterministic checks
Not all parts of an LLM system behave the same way. Some can be tested using standard testing methods, while others require different evaluation approaches.
Deterministic checks (predictable):
- API responses
- Data flow between components
- Output format (for example, JSON structure)
Non-deterministic checks (LLM behavior):
- Answer quality and relevance
- Completeness of response
- Reasoning or explanation
- Tone and phrasing
Understanding this difference is key when you evaluate LLM outputs. You don’t need to treat the entire system as non-deterministic. Instead, separate what can be tested traditionally from what requires LLM evaluation methods. This makes the evaluation process more practical and easier to scale.

One recurring point in industry discussions is the importance of separating what can still be tested deterministically from what cannot. Treating everything as non-deterministic leads to loss of control, while forcing deterministic checks on LLM outputs leads to brittle evaluation.
Key LLM Evaluation Methods Teams Use
There is no single method to evaluate an LLM. In practice, teams combine different methods depending on the application, dataset, and required level of control. Each method answers a slightly different question and usually works best in combination with others. Let’s take a look at the five LLM evaluation methods teams in 2026 swear by.
Rule-based and heuristic evaluation
This is the most structured and predictable method. It relies on predefined rules to evaluate LLM outputs, such as:
- Keyword presence or absence
- Required phrases or constraints
- Output length limits
- Format checks (for example, valid JSON)
This method works well for enforcing strict requirements, especially when the LLM output needs to follow a defined structure.
Where it fits:
- Formatting validation
- Compliance checks
- Simple correctness rules
Limitations:
- Does not capture meaning or quality
- Breaks easily with variation in phrasing
Semantic evaluation
Semantic evaluation focuses on meaning rather than exact wording. Instead of checking for specific phrases, it evaluates whether the LLM output is similar in intent or content to a reference answer.
Typical approaches include:
- Similarity scoring
- Embedding-based comparison
This makes it more suitable for evaluating LLM outputs that can vary in wording but still be correct.
Where it fits:
- Flexible answers
- Paraphrased responses
- Knowledge-based tasks
Limitations:
- May miss subtle errors
- Depends on the quality of reference answers
Human evaluation
Human review remains one of the most reliable ways to evaluate an LLM. It is used to assess aspects that are difficult to measure automatically:
- Usefulness of the answer
- Clarity and readability
- Tone and appropriateness
- Edge-case handling
Where it fits:
- Early-stage evaluation
- High-risk use cases
- Calibration of other methods
Limitations:
- Time-consuming
- Difficult to scale
- Subjective without clear criteria
Human expertise, AI-driven testing, or both — we’ll find the perfect approach to test your app

LLM as a judge
This method uses an LLM to evaluate LLM outputs.
A second model (or the same model with a different prompt) is used to score or judge the quality of responses based on defined criteria. This approach is often used to scale evaluation when human review is not practical.
Where it fits:
- Large datasets
- Automated evaluation workflows
- Comparing multiple versions of an LLM
Limitations:
- Requires careful prompt design
- Evaluation quality depends on the judge LLM
- Results may vary without calibration
This approach is widely discussed as a way to scale evaluation, but QA professionals also note that it requires careful setup. Without clear criteria and calibration, LLM judges can produce inconsistent evaluation scores.
Task-based evaluation
Task-based evaluation focuses on outcomes rather than outputs. Instead of asking whether the answer is correct, it asks whether the LLM helped complete the task.
Examples:
- Did the user get the information they needed
- Was the issue resolved
- Did the workflow complete successfully
Where it fits:
- Production LLM applications
- AI agent evaluation
- End-to-end evaluation of generative AI applications
This method connects LLM evaluation directly to real-world performance and is often the most relevant for business use cases.
Here is a quick breakdown of which evaluation method to use and when.
| Method | What it catches | What it misses | Best for |
| Rule-based | Format errors, missing fields | Meaning, nuance | Structured outputs, constraints |
| Semantic | Relevance, paraphrasing | Subtle inaccuracies | Knowledge answers, flexible phrasing |
| Human | Tone, usefulness, edge cases | Scalability | High-risk scenarios |
| LLM as a judge | Overall quality, coherence | Bias, inconsistency | Large datasets, comparisons |
| Task-based | Real user outcomes | Output-level detail | End-to-end workflows |
LLM Metrics and What You Can Measure
Methods define how you evaluate an LLM. Metrics define what you measure.
This is where many teams get stuck. It’s relatively easy to run evaluation workflows. It’s much harder to decide what “good” actually means and how to measure the performance of your LLM in a consistent way.
Without the right metrics, problems like hallucinations, formatting failures, or quality drift stay invisible until users notice them.
Core metrics used in LLM evaluation
Most teams evaluate LLM outputs across a few common dimensions.
Accuracy/correctness
- Is the information factually correct?
- Does the LLM output contain errors or unsupported claims?
Relevance
- Does the answer address the question?
- Is unnecessary information included?
Completeness
- Is the response fully answering the request?
- Are important details missing?
Consistency
- Does the LLM perform similarly across multiple runs?
- Are the results stable across the same dataset?
Format adherence
- Does the output match the required structure?
- Is the format usable by downstream systems?
Safety and constraints
- Does the output avoid harmful or inappropriate content?
- Does the LLM handle restricted queries correctly?
One of the most common questions from teams is what to measure in the first place. When it comes to practice, there is no single metric that defines LLM performance, which is why evaluation usually combines several signals instead of relying on one score.
Task-specific metrics
Generic metrics are useful, but they are not enough to assess an LLM in a real application. This is why each LLM application needs task-level evaluation.
Examples:
- Support assistant: Issue resolution rate
- Knowledge assistant: Correctness of retrieved answers (RAG evaluation)
- Content generation: Usefulness and edit effort
- AI agent: Successful task completion
This is where LLM evaluation connects directly to business outcomes.
Testing AI applications in 2026: New blog post

Metrics vs. benchmarks
Benchmarks are often used in model evaluation, but they serve a different purpose.
- Metrics — measure performance within your LLM application
- Benchmarks — compare different LLMs using standardized datasets
Benchmarks like public LLM benchmarks can help select a model, but they do not guarantee that the LLM will perform well in your specific use case.
What to keep in mind
Choosing the right metric for LLM evaluation is not about finding a perfect score. It’s about defining evaluation criteria that reflect how your LLM is used. Speaking from experience, effective evaluation uses:
- Multiple metrics instead of one
- A consistent evaluation dataset
- Clear scoring logic for comparison
This allows you to track evaluation results over time and determine if your LLM performs better or worse after changes. Without that, even detailed evaluation methods won’t give you a reliable picture of LLM performance.
Here is a quick look at LLM metrics and the real risk they carry.
| Metric | What it measures | Typical failure signal | Business impact |
| Accuracy | Factual correctness | Confident but wrong answers | Loss of trust |
| Relevance | Query matching | Off-topic responses | User frustration |
| Completeness | Answer coverage | Missing key info | Repeat queries |
| Consistency | Stability across runs | Different answers to same input | Unpredictability |
| Format adherence | Structure compliance | Broken JSON or schema | System failures |
| Safety | Handling of restricted content | Unsafe or policy-breaking output | Compliance risk |
Offline vs. Production Evaluation: What Changes Exactly?
LLM evaluation does not stop after testing. What changes is where and how you evaluate an LLM.
Most teams rely on two layers: offline evaluation for control and production evaluation for reality. Both are needed to understand LLM performance.
Evaluating LLM offline
Offline LLM evaluation happens in a controlled environment using a fixed dataset.
You run evaluation workflows against a test dataset and compare evaluation results across versions of your LLM, prompts, or configuration.
Typical use:
- Comparing different LLMs or prompts
- Running regression checks
- Validating changes before release
Strengths:
- Repeatable and consistent
- Easy to track evaluation scores over time
- Good for controlled experiments
Limitations:
- Limited to known scenarios
- May not reflect real user behavior
Offline LLM evaluations are useful for baseline control, but they do not show how the LLM handles unexpected input.
Evaluating LLM in production
Production evaluation happens on real user interactions inside your LLM application.
Instead of a fixed dataset, you evaluate LLM outputs using live data, logs, and traces.
Typical use:
- Monitoring LLM performance in real conditions
- Identifying new failure cases
- Expanding the evaluation dataset
Strengths:
- Reflects actual usage
- Reveals edge cases and unexpected behavior
- Supports continuous evaluation
Limitations:
- Harder to control
- Evaluation criteria may be less consistent
In practice, production evaluation helps answer a different question: whether an LLM performs well in real scenarios, not just in controlled tests.
Combining offline and online LLM evaluation gives a more complete view of performance and helps maintain quality over time.
LLM Evaluation Frameworks and What They Can Do
| Situation | Do you need a framework? | Why |
| Early prototype | No | Manual evaluation is enough |
| Small dataset (under 50 cases) | No | Simple workflows work |
| Growing dataset | Maybe | Tracking becomes harder |
| Multiple prompts/models | Yes | Comparison becomes critical |
| Continuous updates | Yes | Need repeatable evaluation |
| Prediction monitoring | Yes | Observability required |
LLM testing frameworks are not mandatory to get started, but they become useful as the evaluation process grows. At a basic level, a framework helps you run evaluation workflows at scale, track evaluation results, and compare how an LLM performs across changes. Instead of manually checking outputs, you get a structured evaluation system.
What frameworks really do
Most LLM evaluation frameworks focus on a few core capabilities:
- Running evaluation on a dataset automatically
- Applying evaluation methods and scoring logic
- Storing evaluation results and scores
- Comparing versions of an LLM, prompts, or configurations
This simplifies the end-to-end evaluation of generative AI applications, especially when the evaluation process becomes continuous.
Top frameworks by category
As is often the case with testing frameworks and tools, there isn’t a single framework that can be called the best one. Different tools focus on different parts of the evaluation process, so the team working on testing LLM applications can create the ideal set based on their needs. Here are the most common types of LLM evaluation frameworks and what they do.
General-purpose evaluation frameworks
- Support multiple evaluation methods
- Useful for broad LLM evaluation tasks
Examples:
- DeepEval (open-source LLM evaluation with test cases and scoring)
- Giskard (focused on testing and evaluating LLM behavior)
- Deepchecks (model evaluation adapted for LLM use cases)
RAG evaluation frameworks
- Focus on context relevance and grounding
- Used for rag-based LLM applications
- Measure whether the LLM uses retrieved data correctly
Examples:
- RAGAS (metrics for context relevance, faithfulness, answer quality)
- TruLens (evaluation and tracking for RAG pipelines)
Observability and tracing tools
- Track how an LLM behaves in production
- Capture inputs, outputs, and evaluation data
- Help identify new failure cases
Examples:
- LangSmith (evaluation, tracing, and debugging for LLM apps)
- Langfuse (open-source observability and evaluation tracking)
- Arize Phoenix (monitoring and evaluation for LLM systems)
Lightweight setups
- Custom scripts or simple evaluation workflows
- Often built around existing testing tools
- Useful for smaller LLM applications
Examples:
- Pytest-based evaluation scripts
- Custom pipelines built around OpenAI or other LLM APIs
What Teams Often Get Wrong About Evaluating LLMs
Most issues with LLM applications don’t come from the model itself, but from how evaluation is approached. Teams often assume that if the LLM produces good-looking outputs in a few cases, the system is ready. In reality, gaps in evaluation show up later and are much harder to fix.
The most common mistakes include:
- Treating LLM outputs like traditional test cases. Expecting exact matches instead of evaluating meaning, usefulness, and acceptable variation.
- Relying on manual checks only. Testing a few prompts without a dataset or repeatable evaluation process.
- Focusing on happy paths. Ignoring edge cases, ambiguous inputs, and failure scenarios that matter most in production.
- Not tracking changes over time. Running evaluation once, without comparing results after prompt or model updates.
- Mixing system testing with LLM evaluation. Applying the same approach to APIs, UI, and generated outputs instead of separating concerns.
- Treating evaluation as a one-time step. Skipping continuous evaluation and missing gradual drops in LLM performance.
- Ignoring real user behavior. Building evaluation datasets from synthetic prompts instead of actual usage patterns.
Best Practices for Evaluating an LLM
LLM evaluation does not need to be complex, but it does need to be intentional because most issues come from unclear expectations and inconsistent evaluation, not from a lack of tools. Here are the industry-proven best practices for evaluating LLMs.
Start with real inputs, not synthetic examples
Evaluation is only as good as the dataset behind it. Real user queries, production logs, and known failure cases reveal how the LLM actually behaves in an application. Synthetic prompts can help early on, but they rarely capture the variability and edge cases that appear in real usage.
Define evaluation criteria before running tests
Many teams begin evaluating LLM outputs without clearly defining what a good result looks like. This leads to inconsistent scoring and unclear conclusions. Defining evaluation criteria upfront — what counts as correct, useful, or unacceptable — makes evaluation results easier to compare and act on.
Combine methods instead of relying on one
No single method can fully evaluate an LLM. Rule-based checks help enforce structure, semantic evaluation captures meaning, and human or LLM judges provide context and nuance. The most effective approaches combine these methods rather than relying on just one.
Track changes, not just results
A single evaluation run does not say much about LLM performance. What matters is how results change over time. Running the same dataset across different versions of an LLM or prompt setup allows you to detect regressions and understand whether the system is improving.
Add failure cases back into the dataset
Evaluation improves when it reflects real failures. When an LLM output does not meet expectations in production, that case should be added to the evaluation dataset. Over time, this turns the dataset into a more accurate representation of real-world behavior.
Separate system testing from LLM evaluation
Not every part of an LLM system needs the same approach. APIs, data flow, and formatting can still be tested using traditional methods. LLM evaluation should focus on generated outputs, where behavior is non-deterministic and harder to assess.
Don’t over-engineer early
You do not need a full evaluation framework to get started. A small dataset, clear evaluation criteria, and a simple evaluation process are enough to begin evaluating LLM outputs in a structured way. More advanced evaluation workflows can be added as the application grows.
Focus on task outcomes, not just outputs
It is easy to evaluate whether an answer looks correct, but that is not always what matters most. The more useful question is whether the LLM helped complete the task. Evaluation that focuses on outcomes makes it easier to connect LLM performance to real application value.
Our Experience With Evaluating LLM Systems
LLM evaluation becomes much clearer when applied to real systems.
In our projects, testing is not limited to checking isolated prompts. We evaluate how an LLM performs across real workflows, different user scenarios, and repeated interactions. This includes building test datasets from actual use cases, applying multiple evaluation methods, and tracking how LLM outputs change over time.
The goal is not just to assess an LLM once, but to create a repeatable evaluation process that improves consistency, accuracy, and overall LLM performance within the application.
1. AI assistant quality audit for a CI/CD platform
A CI/CD platform introduced an AI assistant to support developers in workflows like build setup, debugging, and test optimization. The assistant worked in isolated cases but showed inconsistent behavior in real usage.
Key challenges
- Inconsistent responses across similar scenarios
- Weak context awareness in multi-step interactions
- Varying quality depending on user expertise level
- Lack of a structured way to evaluate LLM performance
What we did
- Ran an 8-week evaluation combining exploratory testing, regression checks, and usability validation
- Built test scenarios based on real developer workflows (not synthetic prompts)
- Evaluated outputs across different personas (junior to expert users)
- Assessed context awareness, explanation quality, and consistency under realistic conditions
Outcome
- Identified 25 critical issues affecting reliability and user experience
- Improved reply accuracy (from ~65% to ~82%)
- Established a structured evaluation system with reusable test assets and automation coverage
AI assistant quality audit for a CI/CD platform

2. LLM output testing for a B2B sales copilot
A B2B SaaS company launched an LLM-powered sales copilot to generate emails. The tool produced fluent text but failed in real usage.
Key challenges
- Hallucinated product capabilities and pricing
- Inconsistent and off-brand messaging
- Biased outputs in some cases
- No clear way to evaluate LLM outputs or measure quality
What we did
- Implemented a custom LLM evaluation framework focused on:
- Prompt testing
- Output quality scoring
- Bias detection
- Created a library of edge-case prompts and evaluation datasets
- Introduced scoring for accuracy, tone, and safety
- Added regression-style evaluation to track changes over time
Outcome
- Reduced hallucinations by 60%
- Improved response accuracy by 35%
- User satisfaction increased from 6.5 to 8.7
- Active usage gre by 40%
LLM output testing for a B2B sales copilot
Final Thoughts
LLM evaluation is less about control and more about visibility. You are not trying to force a probabilistic system into perfect behavior — you are trying to understand how it behaves, where it fails, and how those failures change over time. Teams that succeed with LLMs are not the ones with the most advanced models, but the ones that can clearly see what their systems are doing.
What makes this challenging is also what makes it valuable. LLMs introduce flexibility, but they also remove certainty. Evaluation is what brings structure back into that equation. Not by simplifying the problem, but by making it measurable enough to manage.
FAQ
 How do you know if an LLM is actually good enough to release?
How do you know if an LLM is actually good enough to release?
You don’t rely on a single test. If the LLM performs consistently across real scenarios, handles edge cases reasonably, and doesn’t degrade after changes, it’s usually ready for controlled release.
Why does my LLM sometimes give different answers to the same question?
Because LLMs are non-deterministic. Small variations in phrasing or internal sampling can change outputs. Evaluation focuses on acceptable behavior ranges, not identical responses.
Can LLM evaluation be fully automated?
Not completely. Automation helps with scale and consistency, but human review is still needed for quality, tone, and usefulness, especially in early stages or sensitive use cases.
Should I use an LLM to evaluate another LLM?
You can, especially for large datasets. But results depend on prompt design and consistency, so it’s better used alongside other methods rather than on its own.
What matters more, accuracy or usefulness?
In most applications, usefulness wins. An answer can be technically correct but not helpful. Good evaluation looks at whether the LLM actually helps complete the task.
Jump to section
Hand over your project to the pros.
Let’s talk about how we can give your project the push it needs to succeed!


