Retrieval-Augmented Generation (RAG) is a system architecture that combines information retrieval with text generation.
Now, here’s the problem behind this article: LLMs know Wikipedia, not your business. Ask about your return policy, they’ll explain Amazon’s instead.
RAG fixes this by letting AI actually look up your real information before answering. But now you’re testing two things: can it find the right documents, and can it understand them correctly?
That’s why RAG testing matters.
Unlike traditional large language models, RAG applications need to find the right information AND synthesize it correctly. It creates evaluation challenges that standard assessment methods miss.
Updated: September 2025.
Created by: Igor Kovalenko, QA Team Lead and Mentor, Oleksandr Drozdyk, ML Lead, Gen AI Testing Expert; Sasha Baglai, Content Lead.
TL;DR: Quick Summary
RAG testing isn’t LLM testing. Treat retrieval and generation as separate systems. Prove you fetch the right docs before you tune prompts or models.
This guide gives you a practical evaluation playbook: clear metrics, small-but-strong test sets, grounding checks, CI/CD automation, and production SLOs.
Best for: CTOs, QA leads, ML engineers, and product owners who need auditable accuracy claims, fewer support tickets, and safer releases — without guesswork.
#1. Separate failure classes. Retrieval errors ≠ generation errors. Fix the right thing.
#2. Prove retrieval first. Validate that the right docs are fetched before tuning prompts.
#3. Define “ground truth.” Create clear labeling rules (strict vs. lenient) for relevance and correctness.
#4. Cover the corpus. Sample test cases across products, policies, formats, and dates—not just the happy path.
#5. Version everything. Index, embeddings, rerankers, prompts, models, and evaluation sets must be versioned.
#6. Track retrieval quality. Use Precision@K, Recall@K, NDCG, and MRR; monitor them per topic and over time.
#7. Test ranking, not just recall. Users read top results. Bad ordering kills answer quality.
#8. Add rerankers deliberately. Measure uplift from BM25 → vector → hybrid → reranker. Keep what moves the metric.
#9. Evaluate citations. Score support coverage (how many claims cite) and citation correctness@K.
#10. Guard against truncation. Stress-test context windows; verify no key fields fall off the prompt.
Why Enterprises Invest in RAGs: LLM vs RAG
Traditional LLMs are prediction engines. They use transformer architecture and statistical patterns to predict the next most likely word based on their training data.
LLMs aren’t smart — they’re fancy autocomplete.
When you ask ChatGPT, “What’s the standard vacation policy for tech companies?” it doesn’t look up actual HR policies.
It predicts what words should come next based on thousands of policy documents it saw during training.
This is why they hallucinate: they’re designed to always complete the sentence, even when they should say “I don’t know.”
RAG: Give your AI a library card
People expect LLMs to work like Google + a smart assistant. Ask a question, get accurate information. But (again!) LLMs don’t look things up — they just predict plausible text based on training patterns.
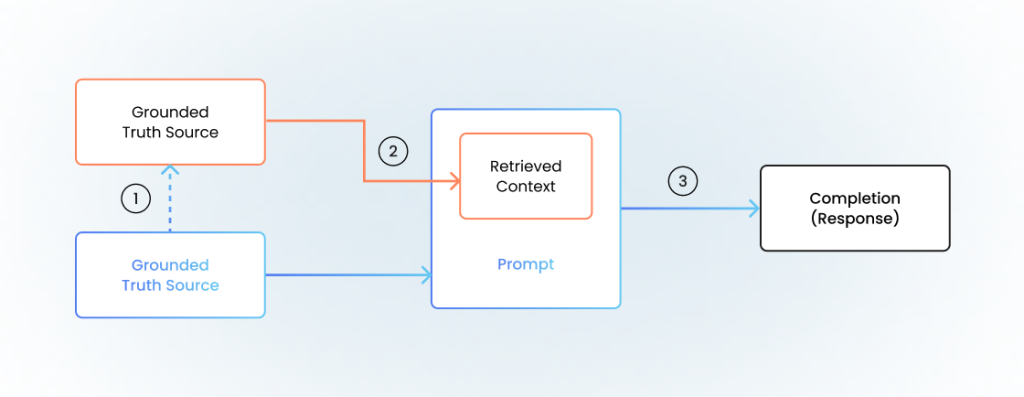
RAG fixes this by making the AI actually research before responding:
Parse the question. Turn “What’s our return policy?” into a database query.
Retrieve real information. Pull actual policy documents from your knowledge base.
Generate with context. Combine the question + retrieved documents to create the response.
Verify accuracy. Check that the answer only uses information from the retrieved sources.
Instead of guessing what your return policy might be, the AI looks it up in your actual policy documents.
The fundamental difference:
LLMs: Pattern prediction based on training data (no actual information retrieval)
RAG: Information lookup + pattern-based synthesis
This creates the core testing challenge: you’re testing whether an AI can actually research information correctly, not just whether it can produce convincing text based on statistical patterns.
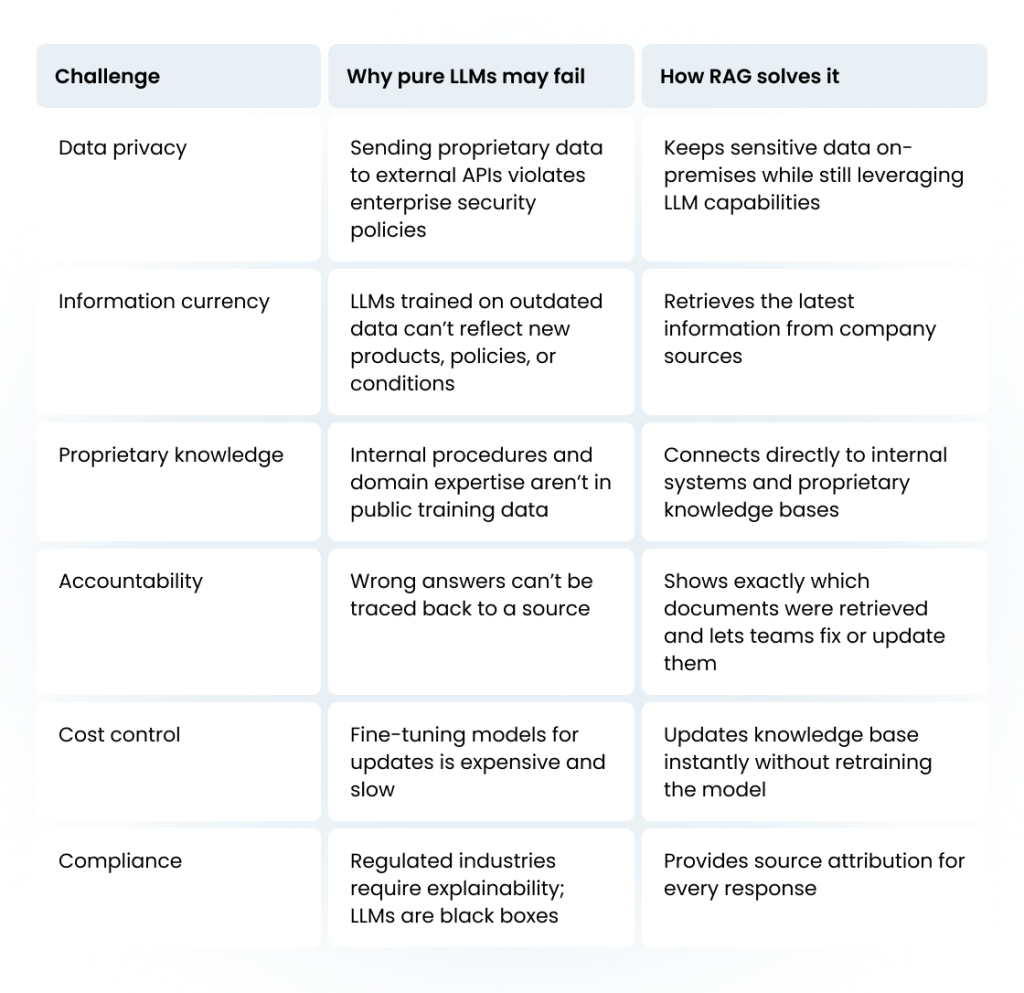
Why enterprises can’t just use LLMs
Traditional LLMs create several business problems that RAG solves:
This is why most enterprise AI deployments use RAG architectures — they need the power of modern language models but with enterprise-grade data control, current information, and explainable results.
Why Add Quality Control to RAG
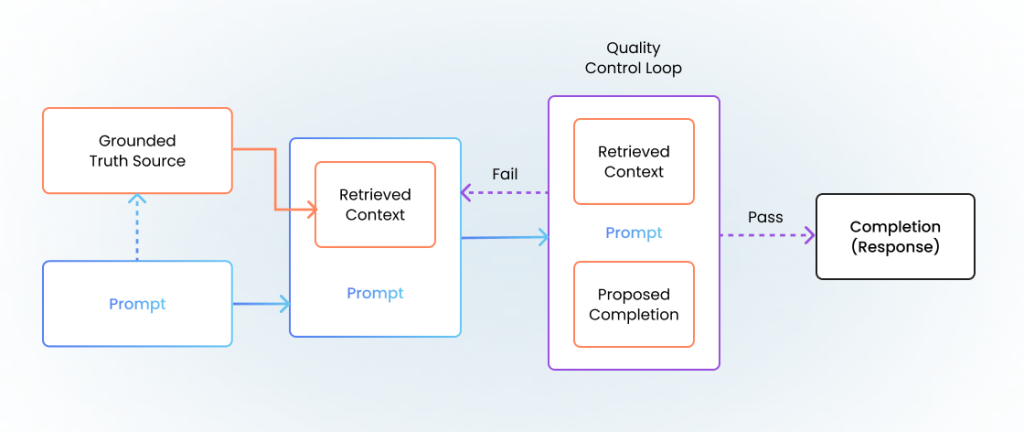
Basic RAG can still mess up — it might retrieve the right documents but misinterpret them, or confidently combine information that shouldn’t be combined. That’s where quality control loops come in.
The quality control step After generating a response, feed both the answer and the original retrieved documents back to the AI with this instruction: “Does this response contain only information from these source documents? Flag any additions or contradictions.”
Without quality control, your RAG system might retrieve your actual return policy document but then add helpful “suggestions” that aren’t in the policy. With quality control, it catches these additions before they reach users.
Multiple loops You can run this check multiple times:
Loop 1: “Is this response grounded in the sources?”
Loop 2: “Is this response complete enough to answer the question?”
Loop 3: “Does this response maintain appropriate tone and format?”
Each quality loop improves accuracy but adds response time and costs more tokens. Most systems use 1-2 loops maximum.
Think of it like having a fact-checker review the AI’s work before publishing. It’s not foolproof, but it catches most of the obvious mistakes that could embarrass you in front of users.
Implementing RAG testing in-house?
We provide AI testing services that catch the hallucinations and edge cases your internal QA might miss.
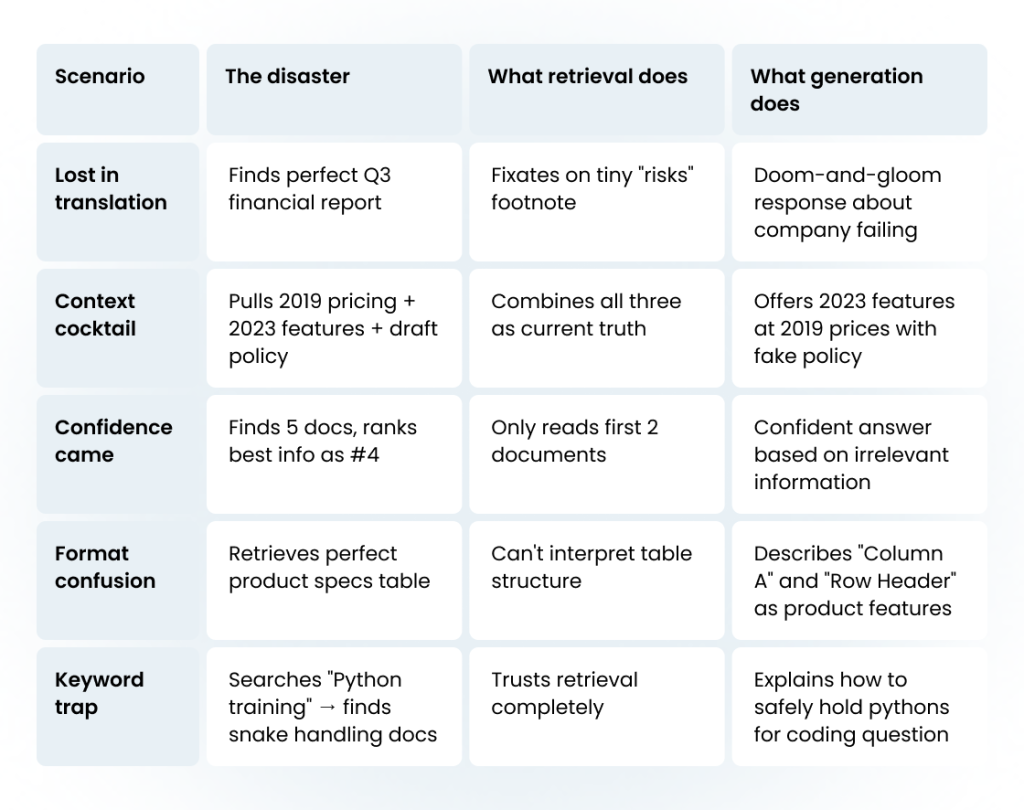
Scenario #1. A healthcare company’s generative AI confidently tells patients that a discontinued medication is still safe to use.
Scenario #2. A financial services chatbot gives contradictory investment advice in the same conversation.
Scenario #3. A legal research tool misses the one case that could win a lawsuit.
This is what happens when evaluating RAG systems fails, particularly in applications where accuracy is crucial.
What’s (extra!) frustrating is that these systems often work beautifully in demos:
they answer prepared questions perfectly,
handle common scenarios with ease,
impress stakeholders with their apparent intelligence.
But put them in front of actual users with real questions, and cracks start to show.
The problem is that most teams are applying traditional LLM evaluation techniques to a fundamentally different technology.
When a basic large language model hallucinates, it might generate creative but obviously wrong content. When a RAG system fails, it presents incorrect information as if it came straight from your trusted knowledge base.
“The AI made something up” = annoying
“The AI says our company policy is X when it’s actually Y” = business liability.
Testing RAG applications with the right evaluation criteria and robust methodologies, you can build assessment frameworks that catch problems early and prove your accuracy claims.
What Makes Testing RAG Application Architecture Different
Think of traditional LLMs as brilliant but isolated writers who work entirely from memory.
RAG systems, on the other hand, are like researchers with access to a vast library — they can look things up, cross-reference sources, and synthesize information from multiple documents.
This fundamental difference changes everything about how we need to test them.
RAG vs Traditional LLM architecture
A RAG system has three core components that all need testing:
The Retrieval component acts as your system’s research assistant. It includes:
Document processing pipelines that chunk and index your knowledge base;
Vector storage systems that convert text into searchable embeddings;
Search engines that find relevant information based on user queries.
When this component fails, you get situations where the AI can’t find relevant information even when it exists in your database.
The Generation component takes retrieved information and crafts coherent responses. It handles:
Context integration (deciding which retrieved documents are most relevant)
Response synthesis (combining information from multiple sources)
Maintaining consistency in tone and style
Poor generation testing leads to responses that are technically accurate but confusing or contradictory.
The Integration Layer coordinates between retrieval and generation, managing data flow, handling edge cases, and optimizing performance. This is where many subtle but critical failures occur — like when the system retrieves the right documents but fails to pass the most important information to the generator.
How to evaluate RAG and LLM
This architecture creates testing challenges that don’t exist with traditional LLMs:
Dual-component complexity means when something goes wrong, you’re not sure which part broke.
Did your system fail to find the right documents, or did it find them but totally misunderstand what they said? It’s like trying to figure out if a bad restaurant experience was due to poor ingredients or a terrible chef — both could ruin your meal.
Variable retrieval results make testing unpredictable.
Ask your system “What’s our vacation policy?” on Monday and it might pull up the HR handbook. Ask the same question on Friday after someone uploaded new policy documents, and it might grab completely different files. Your test results can change even when your code doesn’t.
Context dependency means your RAG system is only as good as your document organization.
If your company knowledge base is a mess of poorly titled PDFs and inconsistent formatting, your AI will give messy, conflicting answers.
Real-time accuracy requirements create a moving target for testing.
Your system needs to handle new documents being added, old ones being updated, and changing user needs. Unlike a traditional model that stays the same once trained, RAG systems are constantly dealing with fresh information that could break existing functionality.
RAG systems have more moving parts, and each part can break in different ways. Now let’s look at how actually to test these unpredictable beasts.
Words by
Oleksandr Drozdyuk
“My north stars: p95 latency and grounding error rate. Pretty answers that arrive late or invent facts are failures.”
What Are The Core Retrieval and Generative AI Testing Methodologies
Testing RAG systems requires a multi-layered approach that would make a software architect proud. You can’t just throw some test queries at your LLM application and call it a day.
Instead, you need to systematically test each component, their interactions, and the complete user experience.
Let’s break this down into manageable pieces that form a practical evaluation framework.
Unit testing: Testing components in isolation
Effective RAG assessment starts at the component level. And this is where many teams make their first mistake — they move straight to end-to-end testing without understanding where problems originate.
For the retrieval component, focus on quantitative metrics like precision and recall.
Fundamental RAG Metrics: Evaluate System Performance Precision measures whether retrieved documents are actually relevant to the query. Recall measures whether you’re finding all the relevant documents that exist in your knowledge base.
Create a testing framework with queries and manually verified “ground truth” documents that should be retrieved.
For a customer support RAG system, you might test queries like “how do I reset my password” and verify that it retrieves the correct help articles, not general security documentation.
import pytest from typing import Set from my_rag_app import retrieval_system, Document
def test_retrieval_precision() -> None: “”” Ensure the retrieval system returns mostly relevant documents for a password reset query. “”” query = “password reset procedure” expected_ids: Set[str] = {“help_password_reset.pdf”, “account_security.pdf”}
# Retrieve top 5 documents retrieved_docs = retrieval_system.search(query=query, top_k=5) assert retrieved_docs, “Expected at least one document to be retrieved.”
# Compute precision relevant = [doc for doc in retrieved_docs if doc.id in expected_ids] precision = len(relevant) / len(retrieved_docs)
# Enforce an 80% precision threshold assert precision >= 0.8, f”Precision too low: {precision:.2f} < 0.8″
For generation testing, evaluate the quality of rag outputs using metrics like faithfulness, coherence, factual accuracy, and relevance. Use automated tools to check whether generated responses stay grounded in the retrieved context and don’t introduce information not present in the source documents.
Test components separately before you test them together.
This is where the most bugs hide when evaluating RAG systems. Integration testing focuses on how retrieval and generation work together, and you’ll be amazed at the creative ways these components can misunderstand each other, especially in complex RAG scenarios.
Mock frameworks are invaluable here for robust testing.
You can simulate various retrieval scenarios — like retrieving contradictory documents or incomplete information — and test how your generation component handles these edge cases. Tools like LangChain can be particularly helpful for orchestrating these test scenarios.
from unittest import mock from my_rag_app import rag_system, Document
@mock.patch(“my_rag_app.retrieval_system.search”) def test_handle_contradictory_sources(mock_search) -> None: “”” Verify that the RAG system gracefully handles conflicting policy documents. “”” # Simulate two contradictory source documents mock_search.return_value = [ Document(id=”policy_a”, content=”Policy A: Remote work allowed.”), Document(id=”policy_b”, content=”Policy B: Remote work requires approval.”) ]
# Generate a response to a policy question response = rag_system.generate_response(“What’s our remote work policy?”) text = response.lower()
# Expect the system to acknowledge or resolve the conflict assert “conflict” in text or “varies” in text or “either” in text, ( “Response should mention conflicting policies or variation.” )
Data pipeline validation ensures that information flows correctly between components throughout the rag pipeline. Test scenarios where documents are updated, deleted, or corrupted to ensure your system degrades gracefully rather than failing silently.
Think of this as testing the conversation between your retrieval and generation systems. Are they speaking the same language? Do they handle disagreements gracefully? Can they recover when one of them has a bad day?
Need proven AI testing results?
TestFort’s approach eliminated 90% of recurring defects and increased test coverage by 40% for a Finnish hardware manufacturer in a 2-week project.
Now for the final boss level: testing your complete RAG system under realistic conditions for performance evaluation. This includes testing with actual user queries, realistic knowledge bases, and production-like loads where accuracy and reliability matter most.
Create comprehensive test scenarios that cover:
Common user workflows
Edge cases
Performance under load
The typical user interaction patterns and the responses they expect
Ambiguous queries, requests for information that doesn’t exist, and attempts to access restricted content
How your system behaves when handling multiple concurrent queries
Automated user agents can help scale this testing and serve as an effective tool for evaluating rag systems. These AI-powered testing agents can generate diverse queries, evaluate responses, and classify results using the same semantic understanding techniques your RAG system uses.
With your testing methodology sorted, let’s talk about the key metrics that actually matter for measuring RAG performance.
What Are the RAG Essential Evaluation Metrics
Metrics can make or break your RAG evaluation strategy.
Choose the wrong ones, and you’ll optimize for impressive benchmarks that don’t correlate with real user satisfaction.
Choose the right evaluation criteria, and you’ll have clear signals for when your system is ready for prime time.
Retrieval metrics that drive business value
Precision@k measures the percentage of retrieved documents that are actually relevant to the query. It is a fundamental metric used to evaluate retrieval accuracy. For business apps, this directly impacts user trust — irrelevant results make users lose confidence in the system fast.
Recall@k measures whether you’re finding all relevant documents in your knowledge base. Poor recall means users might miss critical information, which can be particularly dangerous in compliance-heavy industries like finance or healthcare.
Normalized Discounted Cumulative Gain (NDCG) considers both relevance and ranking order. This metric matters because users typically focus on the first few results, so having relevant documents ranked highly is crucial for user interaction and experience.
Translating Quantitative Metrics to Real Business Impact
High precision = Users trust the system results
High recall = Users don’t miss important information
High NDCG = Users find what they need quickly
Think of it this way: precision keeps users happy, recall keeps you compliant, and NDCG keeps users productive.
Generation metrics for quality assurance
BLEU and ROUGE scores measure linguistic quality by comparing generated text to reference responses.
While useful for baseline evaluation, they don’t capture semantic meaning well, so supplement them with other evaluation techniques.
Semantic similarity using embedding models provides a more nuanced way to evaluate the quality of generated responses.
Use it to assess whether they capture the same meaning as expected answers, even when using different words.
Metrics like faithfulness are crucial for RAG applications and help evaluate quality in generative systems.
Use AI evaluation approaches to check whether generated responses contain information that contradicts the retrieved context:
import textwrap from typing import Any
def make_evaluation_prompt( retrieved_context: str, generated_response: str ) -> str: “”” Build a prompt to check if the generated response contradicts the retrieved context. “”” template = “”” Compare the submitted answer to the source documents. Does the answer contain any information that contradicts the sources?
Sources: {retrieved_context}
Answer: {generated_response}
Rate as: (A) Fully consistent (B) Minor inconsistencies (C) Major contradictions “”” return textwrap.dedent(template).format( retrieved_context=retrieved_context.strip(), generated_response=generated_response.strip() )
System-level metrics for operational excellence
Response latency directly impacts user experience. Measure not just average response time but also 95th and 99th percentile latencies to understand worst-case performance. Nobody cares if your average response time is great if 5% of users wait 30 seconds for answers.
Hallucination detection identifies when your system generates information not present in retrieved documents. This is critical for maintaining trust and avoiding liability issues, particularly in applications where accuracy is crucial.
User satisfaction metrics from actual users provide the ultimate measure of success. Track key metrics like task completion rates, user retention, and explicit satisfaction scores to understand real-world performance of rag systems.
Technical metrics are great for debugging, but business metrics determine whether your RAG system actually succeeds in the real world.
Now let’s talk about how to implement these metrics without building everything from scratch.
How to Implement RAG QA: From Manual Testing to Automation
Ready to stop talking theory and start building? This is where the rubber meets the road for testing RAG applications.
We’ll walk through setting up RAG evaluation from your first manual tests to fully automated evaluation pipelines that run with every code change.
Setting up quality test data
Start by creating curated question-answer pairs that represent real user needs. For a corporate knowledge management system, include questions about company policies, procedures, and frequently asked topics.
Words by
Igor Kovalenko, QA Lead and Mentor, TestFort
“Your evaluation is only as good as your test data — garbage in, garbage out applies double to RAG assessment.”
Synthetic data generation can help scale your test suite when building rag systems. Use LLMs to generate diverse questions based on your document corpus, but always validate a sample manually to ensure quality of llm outputs.
Reusable test-question generator
def generate_test_questions( document_content: str, llm: Any, num_questions: int = 5 ) -> List[str]: “”” Use an LLM to generate a list of realistic user questions from a document. “”” if not document_content.strip(): raise ValueError(“Document content is empty.”) template = f””” Based on this document, generate {num_questions} questions that users might ask: {document_content[:1000]}
Questions should be: 1. Specific enough to have clear answers 2. Varied in complexity and style 3. Realistic for actual users “”” prompt = textwrap.dedent(template) raw_output = llm.generate( prompt=prompt, model=”gpt-4″, temperature=0.7, max_tokens=300 ) questions = [ line.strip().lstrip(“0123456789. “) for line in raw_output.splitlines() if line.strip() ] return questions
Pro tip: Start small with 20-50 high-quality test cases rather than 500 mediocre ones. Quality beats quantity every time in rag evaluation.
Implementing AI-as-judge evaluation
Here’s where things get meta: using AI evaluation with LLMs like GPT-4 to evaluate your RAG responses. This approach scales better than human evaluation while maintaining reasonable accuracy for most use cases and serves as a powerful tool for evaluating rag performance.
Create specific evaluation prompts for different aspects:
Compliance evaluation checks whether generated responses stick to information in retrieved documents:
Compliance prompt
def make_compliance_prompt(context: str, response: str) -> str: “”” Prompt to check whether the response strictly adheres to the context. “”” template = “”” Compare the response to the source documents.
Source: {context}
Response: {response}
Select one: (A) Response only uses information from sources (B) Response adds new information not in sources (C) Response contradicts the sources “”” return textwrap.dedent(template).format( context=context.strip(), response=response.strip() )
Completeness prompt
def make_completeness_prompt(question: str, response: str) -> str: “”” Prompt to check whether the response fully answers the user’s question. “”” template = “”” Does this response completely answer the user’s question?
Question: {question}
Response: {response}
Select one: (A) Completely answers the question (B) Partially answers, missing minor details (C) Partially answers, missing important information (D) Does not answer the question “”” return textwrap.dedent(template).format( question=question.strip(), response=response.strip() )
The beauty of AI evaluation? It’s consistent, scalable, and available 24/7. Just remember to validate its decisions against human judgment periodically through fine-tuning of your evaluation criteria.
Advanced automation with semantic analysis
Ready to level up? Move beyond keyword matching to semantic understanding by using embeddings to evaluate the quality of rag responses. This approach works particularly well for detecting when responses are semantically correct but use different terminology than expected answers.
def evaluate_semantic_similarity( expected: str, generated: str, embedding_model: Any ) -> float: “”” Returns cosine similarity between embeddings of expected and generated answers. “”” if not expected or not generated: return 0.0
Automated test agents can continuously evaluate your RAG system by generating queries, collecting responses, and flagging potential issues for human review. This approach catches regressions early and provides ongoing performance monitoring.
Think of it as having a QA team that never sleeps, never gets tired, and can test thousands of scenarios in the time it takes you to grab coffee.
Now that you know how to implement evaluation, let’s explore the tools that can save you months of development time.
How to Choose Your RAG Testing Stack: Tools and Frameworks
Why reinvent the wheel when brilliant people have already built amazing RAG evaluation tools? The ecosystem has exploded with options, from open-source frameworks to enterprise-grade platforms. Let’s explore what’s available and help you choose the right tool for evaluating rag systems that match your specific needs.
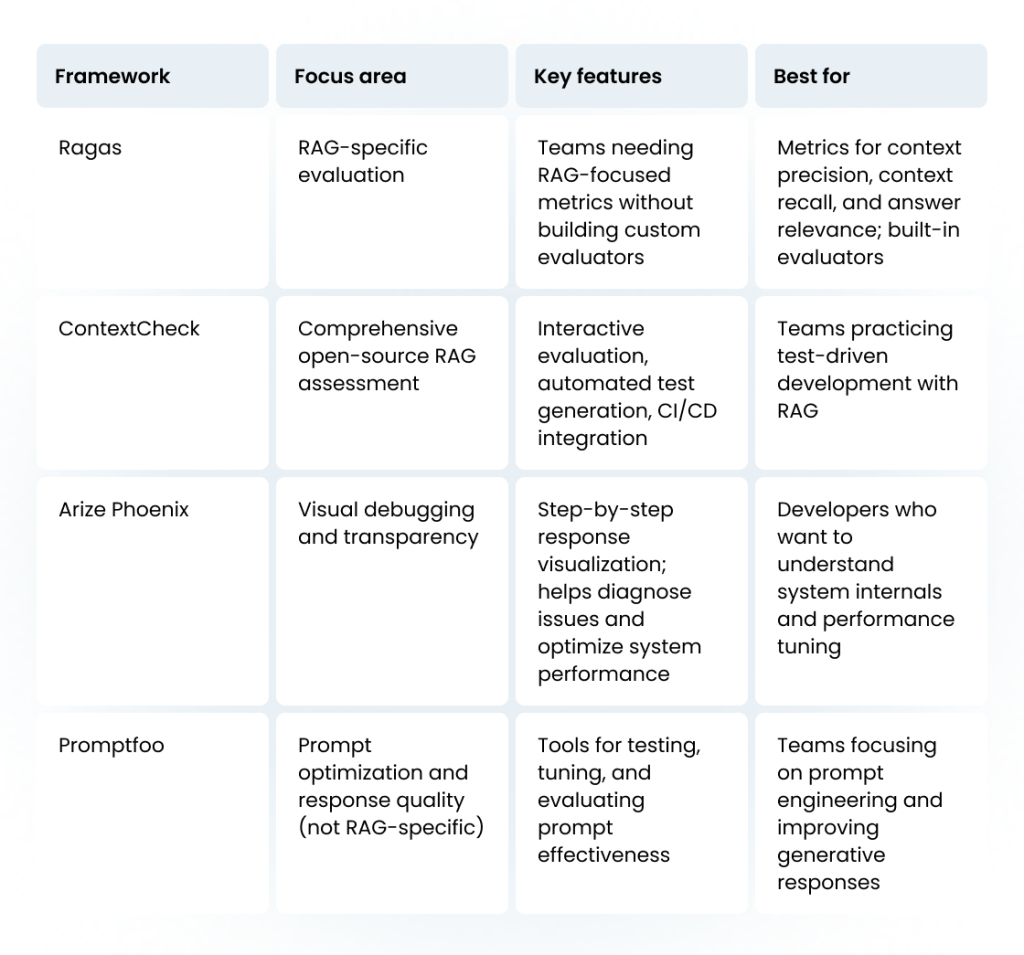
Popular RAG evaluation frameworks
Evaluating retrieval-augmented generation (RAG) systems requires tools that balance technical accuracy with practical usability. Below is a comparison of the most recognized frameworks, each addressing different aspects of RAG evaluation.
Framework selection criteria
Consider these factors when choosing evaluation tools:
Team expertise: Some frameworks require more technical setup than others
Integration requirements: How well does the tool integrate with your existing development workflow?
Evaluation depth: Do you need basic metrics or comprehensive analysis?
Cost considerations: Open-source vs. commercial licensing costs
Scalability: Can the tool handle your expected evaluation volume?
For most teams starting with evaluating rag, beginning with an open-source testing framework like Ragas or ContextCheck provides good functionality while allowing customization as needs evolve.
The key is starting with something that works out of the box and evolving your evaluation strategy as you learn what matters most for your specific llm application.
Let’s now explore the most common mistakes teams make — and how to avoid them.
Words by
Igor Kovalenko, Engineering Quality Lead, TestFort
“Most RAG incidents start in retrieval, not generation. I want proof we fetch the right documents before anyone touches prompts or models. Flashy demos don’t count — only reproducible eval runs do.”
Best Practices
Some teams nail their evaluation strategy and ship reliable systems that users actually trust. Others make predictable mistakes that turn promising AI projects into expensive lessons. The difference usually comes down to a few key decisions made early in the process.
Data quality: The foundation of reliable testing
Clean, diverse datasets are essential for meaningful evaluation. Include edge cases, different query types, and various document formats in your test data. A common mistake is testing only with “happy path” scenarios that don’t reflect real user behavior.
Regular dataset updates ensure your evaluation remains relevant as your knowledge base evolves. Automated monitoring can alert you when document changes might affect existing test cases.
Common mistakes that undermine RAG testing
Over-relying on automated metrics without human validation leads to systems that score well on benchmarks but fail in practice. Always validate automated evaluation results with human reviewers, especially during initial system development.
Ignoring retrieval quality while focusing only on generation metrics misses half the RAG equation. Poor retrieval will limit generation quality regardless of how good your LLM is.
Neglecting edge cases like ambiguous queries, requests for non-existent information, or attempts to access restricted content can lead to system failures in production.
Static evaluation approaches that don’t account for changing knowledge bases and user needs become outdated quickly. Build evaluation processes that adapt as your system evolves.
Continuous improvement strategies
User feedback integration provides real-world validation of your evaluation metrics. Track discrepancies between your automated evaluation scores and actual user satisfaction to refine your testing approach.
A/B testing different RAG configurations helps validate improvements objectively. Test changes like different embedding models, retrieval algorithms, or generation prompts using controlled experiments with real user traffic.
Performance monitoring in production catches issues that testing might miss. Monitor metrics like response latency, error rates, and user engagement to identify problems early.
Frameworks only get you so far.
A QA audit detects where your RAG testing strategy has blind spots and how to address them.
The Business Case: Why RAG Testing Pays for Itself
Proper RAG assessment is a business investment with measurable returns that often surprise executives who initially see it as “just another engineering expense.”
Poor performance of RAG systems costs organizations in multiple ways that add up quickly:
Customer support systems that can’t answer basic questions force users to contact human agents, increasing operational costs. One telecommunications company found that fixing their RAG system’s accuracy reduced support tickets by 35%, saving over $1.2 million annually in agent costs (with taxes, social payment costs, etc.)
Legal research tools that miss relevant precedents create compliance risks and billable hour inefficiencies. A law firm discovered their RAG system was missing almost 20% of relevant case law, potentially compromising client outcomes and exposing the firm to malpractice claims.
Sales assistants that provide outdated pricing information damage customer relationships and create revenue leaks. An enterprise software company found that pricing errors from their RAG-powered sales tool cost them over $300K in deal rework (and hell knows how much in customer trust recovery).
Demonstrating accuracy claims
When marketing generative AI capabilities, saying your system has “95% accuracy” means nothing without rigorous testing to back up that claim. Comprehensive evaluation frameworks provide the evidence needed to make credible performance statements that stand up to customer scrutiny.
Building competitive advantage
Organizations with robust testing capabilities for their rag applications can deploy AI applications confidently, iterate quickly based on data rather than guesswork, and scale systems that actually work rather than managing expensive failures.
The competitive advantage isn’t just about having AI — it’s about having AI that reliably works when users need it most.
RAFT: When Your Model Learns How to Research
Most RAG systems treat the language model like a smart but inexperienced intern—they hand it retrieved documents and hope it figures out how to use them properly.
RAFT (Retrieval-Augmented Fine-Tuning) takes a different approach: it actually teaches the model how to be a better researcher.
How RAFT works
Traditional fine-tuning shows a model lots of question-answer pairs from your domain. RAFT goes further by showing the model question-answer pairs alongside the specific documents that should be used to answer those questions.
The training process:
Take a question from your domain: “What’s our return policy for damaged items?”
Show the model the relevant retrieved documents (return policy PDF, customer service guidelines)
Show the model the correct answer based on those documents
Repeat thousands of times with different questions and document combinations
The model learns two things simultaneously: your domain knowledge and how to extract information from retrieved context. It’s like training a research assistant by showing them both the library and examples of good research reports.
Why RAFT matters for testing
RAFT creates a fundamentally different testing challenge because your model now has opinions about your domain. A standard RAG system using GPT-4 might say “Based on the retrieved documents…” when it’s uncertain. A RAFT-trained model will confidently make statements about your domain, even when the retrieved context is incomplete or contradictory.
Consider a legal RAFT system trained on case law. When asked about a precedent that doesn’t exist in the retrieved documents, it might confidently cite “Johnson v. Smith (2019)” because it learned that legal answers should include case citations. The citation sounds legitimate, follows the right format, but is completely invented.
This creates three new testing requirements:
Domain-specific hallucination detection: Your model will hallucinate in ways that sound correct to non-experts. You need domain experts involved in evaluation, not just general QA testers.
Retrieved vs. learned knowledge conflicts: Sometimes the retrieved documents will contradict what the model learned during fine-tuning. Test how your system handles these conflicts—does it defer to retrieved content or stick with its training?
Confidence calibration: RAFT models often become overconfident in their domain. Test edge cases where the model should admit uncertainty instead of generating plausible-sounding nonsense.
RAFT isn’t just a technical upgrade—it’s a shift toward AI systems that have deep, specialized knowledge about your business. That specialization makes them more useful, but also more dangerous when they fail. Your testing needs to match that reality.
Future-Proofing Your RAG Testing Strategy
Multi-modal RAG systems that handle text, images, and other data types will require evaluation frameworks that assess cross-modal understanding and generation quality. Start thinking about how your current testing approaches will scale to handle visual documents, audio transcripts, and structured data integration.
Adversarial testing approaches will become increasingly important as bad actors try to manipulate RAG systems through prompt injection or data poisoning attacks. Build evaluation processes that can detect when your system is being gamed.
AI-powered test case generation promises to automate much of the tedious work of creating comprehensive test suites. These systems will generate edge cases, simulate user behavior patterns, and identify potential failure modes that human testers might miss.
The key to future-proofing your approach? Build evaluation frameworks that are modular, extensible, and data-driven. Focus on creating systems that can adapt to new metrics, integrate new evaluation tools, and scale with your RAG applications as they grow in complexity and importance to your business.
Wrapping Up: Your RAG Testing Action Plan
We won’t recap the entire article in a few abstracts, we believe you can scroll back and refresh your memory on how to evaluate a RAG app the moment you want to.
Instead, we wanted to give you a practical next-step roadmap for implementing effective evaluation.
Week 1-2: Foundation
Set up basic test data with 20-50 high-quality question-answer pairs;
Choose a testing framework (Ragas or ContextCheck are good starting points);
Implement basic precision/recall metrics for your retrieval component.
Month 1: Automation
Build ai evaluation for response quality using LLM-as-judge approaches;
Set up automated testing in your CI/CD pipeline;
Start collecting baseline performance metrics.
Month 2-3: Optimization
Add semantic similarity evaluation;
Implement user feedback collection and fine-tuning processes;
Begin A/B testing different system configurations.
Ongoing: Evolution
Regular test data updates based on new user queries;
Continuous monitoring and alerting for production performance;
Quarterly evaluation framework reviews and updates.
Remember: testing RAG applications is ultimately about ensuring your AI systems deliver real value to users.
The best evaluation framework is one that helps you build more reliable, trustworthy, and useful AI applications that solve actual problems rather than just demonstrating impressive technology.
The organizations that master RAG assessment early will have a significant advantage as generative AI becomes increasingly central to business operations.
Start testing systematically, measure what matters, and iterate based on real user feedback.
Frequently Asked Questions On RAG Testing
How is testing a RAG system different from testing our regular software?
Regular software testing asks “Does this function work?” RAG testing asks “Does this give the right answer to this question?” You’re testing intelligence and knowledge, not just code logic. You need domain experts involved, not just QA engineers.
We already have a RAG system running. How do I know if it’s actually working?
Start with these red flags: Are users asking the same questions to human support that your RAG should answer? Are you getting complaints about incorrect information? Try asking your system 20 questions you know the answers to — if it gets more than 2-3 wrong, you have a problem.
Do we need to hire AI specialists for RAG testing, or can our regular QA/Devs handle it?
Your existing developers can handle most RAG testing with the right tools. You’ll need someone who understands both your business domain and basic AI concepts, but you don’t need a PhD in machine learning. Think “technically strong product manager” rather than “AI researcher.”
How often do we need to re-test everything when we add new documents?
Depends on your setup. If you have automated testing (recommended), new documents trigger tests automatically. Manual testing should happen monthly for stable systems, weekly for rapidly changing knowledge bases. The key is catching problems before users do.
What’s the minimum we can get away with for testing?
Start with 20-30 high-quality test questions that cover your most common user scenarios. Set up basic accuracy monitoring. Use an existing framework like Ragas rather than building from scratch. You can get meaningful testing running in 2-3 weeks, not months.
Our knowledge base changes constantly. How do we test something that’s always moving?
This is exactly why you need automated testing. Set up continuous evaluation that runs whenever documents change. Focus on testing user workflows rather than specific document content — test “Can users find pricing information?” not “Does it mention the $50 plan?”
Share:
Jump to section
Hand over your project to the pros.
Let’s talk about how we can give your project the push it needs to succeed!
A commercial writer with 13+ years of experience. Focuses on content for IT, IoT, robotics, AI and neuroscience-related companies. Open for various tech-savvy writing challenges. Speaks four languages, joins running races, plays tennis, reads sci-fi novels.



 How is testing a RAG system different from testing our regular software?
How is testing a RAG system different from testing our regular software?