AI Hallucination Testing: Test AI Models for Nonsense
Test LLM, generative AI models and RAGs for hallucination with our AI systems hallucination testing guide. Identify factually inaccurate or nonsensical output.
The essential framework for engineering and QA leaders to transform AI hallucinations from an unavoidable risk into a manageable quality challenge.
Updated: September 30, 2025.
Created by: Igor Kovalenko, QA Team Lead and Mentor;
Oleksandr Drozdyuk, ML Lead, Gen AI Testing Expert;
Sasha Baglai, Content Lead.
What is AI hallucination?
It is any claim that isn’t supported by your sources (for RAG) or is factually wrong/contradictory to domain truth. For RAG specifically, even a “true” statement is ungrounded if it cannot be verified against the provided context.
A hallucination occurs when an AI model generates factually incorrect, logically inconsistent, or entirely fabricated information, yet presents it with absolute authority.
Unlike a traditional software bug, this isn’t a coding error; it’s a byproduct of how generative AI works.
As we integrate these powerful tools into critical fields like healthcare, law, and finance, testing for hallucinations is no longer optional — it’s fundamental to building trust and ensuring safety.
This guide provides a practical framework for detecting, measuring, and mitigating AI hallucinations.
Best for: CTOs, VPs of Engineering, QA Managers, AI/ML Team Leads, Product Managers, Senior QA Engineers, and AI Safety Researchers.
TL;DR: Quick Summary
AI hallucinations — confident but false statements from AI models — are a fundamental challenge in building trustworthy AI. Unlike traditional software bugs, they cannot be fixed with simple code patches; they are a core behavior of how Large Language Models operate. This guide moves beyond theory to provide a practical, multi-tiered testing framework and the cultural playbook necessary to manage this risk effectively, ensuring your AI applications are both powerful and reliable.
Adopt a three-tiered testing strategy. Combine broad automated validation, targeted adversarial probes, and essential human expert review for comprehensive coverage. Don’t rely on a single method.
Prioritize RAG for mitigation. Retrieval-Augmented Generation (RAG) is the most effective technique to ground AI in facts and drastically reduce hallucinations. Make it a core part of your architecture.
Measure what matters. Move beyond simple pass/fail tests. Track concrete metrics like Hallucination Rate, Groundedness Score, and FActScore to quantify risk and measure improvement.
Shift from “Ship Fast” to “Ship Trustworthy.” This is a cultural imperative. No AI feature is “done” until it meets defined hallucination testing benchmarks.
Allocate significant time for testing. Plan for 30-40% of AI development project time to be dedicated specifically to hallucination testing and mitigation. This is not overhead; it’s core to the work.
Systematize your findings. Create a living “hallucination taxonomy” and pattern library within your organization. Classifying errors helps prioritize fixes and prevents recurring issues.
Integrate domain experts. Automation can’t catch nuanced falsehoods. Establish formal processes for subject-matter experts to review high-stakes AI outputs before they reach users.
What Are the Causes of AI Hallucinations?
Summary:Hallucinations arise from the core nature of LLMs. They are sophisticated pattern-matching systems, not fact-checking engines. Their goal is to predict the next most probable word in a sequence, which can lead to plausible-sounding falsehoods. (Source: OpenAI)
AI hallucinations occur when a generative AI system produces outputs that are incorrect, nonsensical, or completely fabricated. These inaccurate outputs are not traditional software bugs but fundamental flaws that can erode trust in ai and lead to the spread of misinformation.
Understanding why hallucinations happen is critical for anyone looking to build a reliable AI tool. This is especially relevant given regulations like the EU AI Act, which mandate higher standards for accuracy and reliability.
From ChatGPT to Bard, no model is immune. The causes are multifaceted, stemming from the data an ai model is trained on, the way it generates AI-generated text, and the instructions it’s given. Effective, rigorous testing must start with a deep understanding of these root causes.
1. Flawed training data (Gaps, Biases, and “Poisoning”)
The foundation of any machine learning model is its data. Hallucinations can occur simply because the model is trained on a flawed dataset. If the training data contains gaps or is biased or unrepresentative data, the ai tool inherits these limitations. The quality of ai responses is directly tied to the quality of its training data.
How it happens: When a model encounters a topic it has little information on, it doesn’t stop; the model may “fill in the blanks” with inaccurate information.
Notable Examples of AI risks in this area include a chatbot for a financial firm trained on a dataset from before 2024 generating false information about market conditions in 2025. This can have serious consequences, especially in specialized fields like medical ai, where incorrect or misleading outputs are dangerous.
2. The probabilistic path (Prediction over fact)
At its core, an LLM is an engine designed to recognize and replicate patterns in their training data. Its primary goal is to generate responses by predicting the next most probable word in a sequence. This process prioritizes fluency over fact, increasing the likelihood of outputs that are factually incorrect.
How it happens: The model is based on patterns, not a knowledge base. A widely-circulated myth might be more “probable” as a sequence of words than a complex scientific truth.
The AI model may confidently generate outputs that contribute to the spread of misinformation simply because the incorrect or fabricated content follows common linguistic patterns.
Words by
Igor Kovalenko, QA Team Lead and Mentor, TestFort
“For years, QA has focused on deterministic bugs — a button either works or it doesn’t. With AI, we’re now testing for probabilistic behavior. A hallucination isn’t a simple failure; it’s a breach of trust. Our job has evolved from bug hunting to becoming the guardians of factual reliability. We’re no longer just asking ‘Does it work?’ but ‘Can we trust what it says?’”
3. Lack of grounding (Ambiguous prompts)
Hallucinations can also be triggered by the user’s instructions. A vague or open-ended prompt creates a lack of grounding, giving the model too much freedom to invent information. Without clear constraints, the model’s creative, pattern-matching nature takes over.
How it happens: Asking a generic chatbot “Tell me about the CEO’s latest project” is less safe than “Summarize the CEO’s Q2 2025 earnings call report.” The second prompt grounds the model in a specific context.
This is why clear prompt engineering is essential. Without it, you can’t ensure that AI systems stay on topic, and verifying their accuracy becomes far more difficult.
4. Overfitting (Memorization without understanding)
Sometimes, the problem is that models are trained too well on specific parts of their data. Overfitting occurs when a model memorizes exact phrases rather than learning underlying concepts. It then regurgitates this memorized content out of context.
How it happens: The model repeats a memorized product description or a historical fact in response to a vaguely similar but different query, leading to a contextually inaccurate answer.
This is one of the more subtle multiple types of hallucinations. The statement might be true in isolation but is false information in the context of the user’s question, highlighting the need to detect ai hallucinations beyond simple fact-checking. This is a key challenge for achieving true explainable AI.
Measures how well the AI’s answer is supported by the specific documents or data it was given. A low groundedness score means the model is ignoring the provided context and inventing information. This is a critical metric to use as a primary gate for any customer-facing RAG application.
RAGAS suite
This framework goes deeper, evaluating both the retrieval and generation steps. It includes metrics like Faithfulness (is the answer consistent with the retrieved context?) and Context Precision/Recall (was the right context retrieved in the first place?). This helps diagnose if hallucinations are caused by poor retrieval or poor generation. (Source: Check RAGAS official documentation).
Words by
Oleksandr Drozdyuk, ML Lead, Gen AI Testing Expert
“From a machine learning perspective, you can’t just ‘patch’ a hallucination. There’s no single line of code to fix. It’s an emergent property of the model’s architecture. That’s why mitigation strategies like RAG are so critical. We’re essentially building guardrails for the model, forcing it to ground its reasoning in a verifiable source of truth instead of its vast, internal world of patterns.”
Advanced metrics for content generation
For long-form content like summaries or articles, you need to verify individual claims.
FActScore
This powerful metric works by breaking a long answer down into “atomic facts.” It then checks what percentage of these individual facts are supported by a reliable, external knowledge source. This is the gold standard for evaluating the factuality of summaries and other long-form generated text.
Self-Consistency / Contradiction Rate
Based on frameworks like SelfCheckGPT, this method involves generating the same answer multiple times with slight variations. It then automatically checks for contradictions between the generated facts. This is highly useful when you don’t have an external source of truth to check against.
Strategic benchmarking
External reference leaderboards. Before committing to a base model, compare candidates on public hallucination leaderboards (like those found on Hugging Face). This helps you select a foundational model that is already optimized for factuality, giving you a better starting point.
How Do You Test and Prevent AI Hallucinations? LLM | RAGs | Chatbot
The most sophisticated testing tools and processes will fail without the right organizational mindset. Creating a culture that takes AI hallucinations seriously requires fundamental shifts in how teams think about development, risk, and success. These changes must be championed from leadership down while being embraced from the ground up. This is where a mature quality engineering approach becomes essential, one that combines automated testing, human oversight, and architectural decisions from day one.
Confident lies eroding user trust?
We implement multi-layered testing to detect and measure AI hallucinations before they reach production.
The tech industry’s “move fast and break things” mentality becomes dangerous when applied to AI systems that can confidently spread misinformation. Organizations must recalibrate their definition of velocity to include reliability as a core component, not an afterthought.
Defining “Definition of done.”
Time investment recognition.
Risk-based release gates.
No AI feature is complete without hallucination testing benchmarks being met. Include specific hallucination metrics in your acceptance criteria.
Allocate 30-40% of AI development time specifically for hallucination testing and mitigation. This isn’t overhead — it’s core development.
Implement mandatory testing checkpoints where hallucination rates must fall below predetermined thresholds before progression.
Creating psychological safety around hallucination discovery
Teams often hesitate to report hallucinations, viewing them as failures. Reframe this narrative by establishing an environment where finding and reporting hallucinations is valued as much as feature development.
Celebrate detection
Blameless post-mortems
Learning repository
Reward team members who identify novel hallucination patterns. Create a “Hallucination Hunter” recognition program.
When hallucinations reach production, focus on system improvements rather than individual accountability.
Maintain a shared database of discovered hallucinations with context, impact, and lessons learned — not as a wall of shame, but as collective wisdom.
Structured Knowledge Management
Gen AI hallucination patterns and testing strategies evolve rapidly, making systematic knowledge management essential. Without proper structure, teams repeatedly encounter the same issues and rediscover the same solutions, wasting valuable time and potentially missing critical patterns.
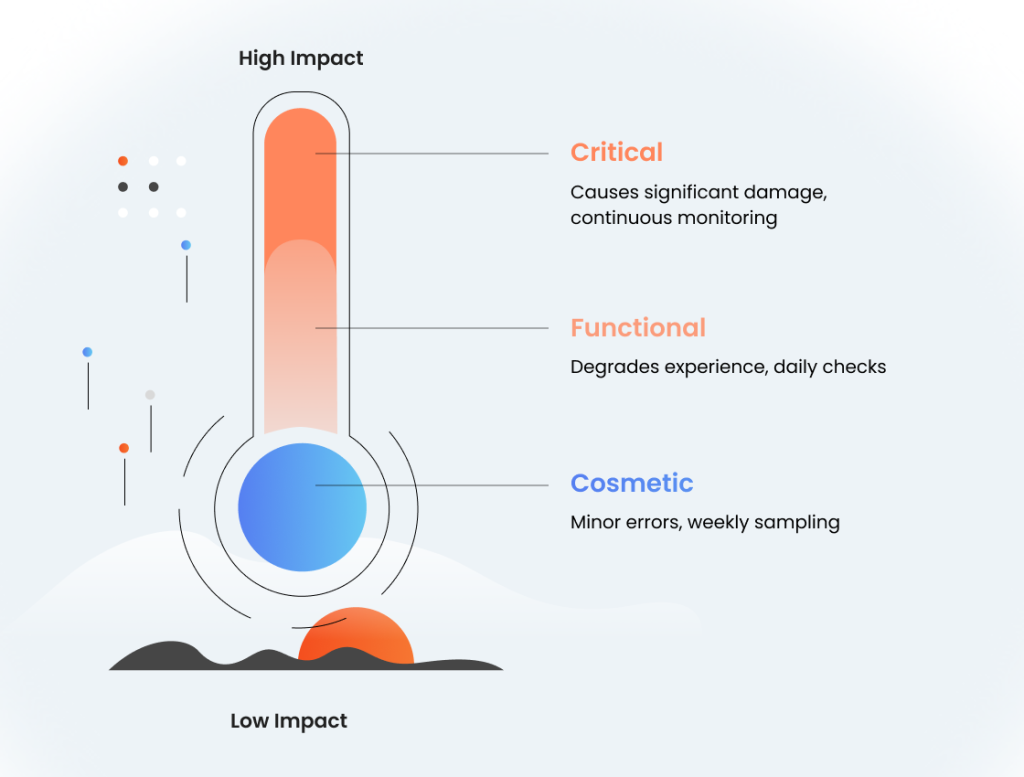
The hallucination taxonomy system
A well-defined classification system helps teams quickly assess risk levels and apply appropriate testing rigor. This taxonomy should be specific to your domain while remaining flexible enough to accommodate new types of hallucinations as they emerge.
Level 1: Cosmetic Hallucinations
Minor factual errors with no user impact;
Example: Wrong middle initial in a historical figure’s name;
Testing frequency: Weekly sampling.
Level 2: Functional Hallucinations
Errors that degrade user experience but don’t cause harm;
Example: Incorrect product specifications in a shopping assistant;
Testing frequency: Daily automated checks.
Level 3: Critical Hallucinations
Errors that could cause financial, legal, or reputational damage;
Example: Wrong medical dosage information;
Testing frequency: Continuous monitoring with immediate alerts.
Living documentation practices
Static documentation quickly becomes obsolete. Instead, create living documents that evolve with your understanding of hallucination patterns and testing effectiveness.
Hallucination pattern library. Document recurring hallucination types with reproducible examples, root causes, and proven mitigation strategies.
Testing playbooks. Create step-by-step guides for testing different AI components, updated quarterly based on new findings.
Decision trees. Build flowcharts that help testers quickly identify which testing methodology to apply based on the AI feature type.
A robust testing strategy for RAG and LLM hallucination detection combines automated scalability with the nuance of human judgment. Think of it as a three-tiered defense against falsehoods.
Tier 1: Broad & Automated Validation
This layer is for continuous, large-scale testing to catch common errors.
Gold standard comparison This is the foundational method. You create a “golden dataset” — a curated list of prompts with verified, correct answers (the “ground truth”). The AI’s outputs are then automatically compared against this dataset to flag factual deviations.
AI-powered grading
A more advanced technique involves using one LLM to evaluate another. You provide a prompt, the AI’s response, and the “expert” answer to a capable model (like GPT-4) and ask it to score the factual alignment. This is surprisingly effective because judging the similarity of two texts is a much simpler task for an AI than generating a factually perfect answer from scratch.
Tier 2: Targeted & Adversarial Probes
This layer focuses on finding specific weaknesses and stress-testing the model’s limits.
Consistency testing Ask the same question multiple times using different phrasing. If the AI provides contradictory answers (e.g., stating a company was founded in 1998 and then 2003), it’s a sign of unreliability.
Adversarial testing Intentionally try to trick the model. Feed it prompts with false premises and see how it reacts. For instance: “Explain how Leonardo da Vinci used his iPhone to sketch the Mona Lisa.” A good response would correct the premise, while a hallucinating response would invent a story.
Specific checks for known issues If you notice a recurring hallucination pattern (e.g., the model frequently invents academic credentials for people), you can build specific, automated checks that run against outputs to look for just that type of error.
Automation can’t catch everything. Human intelligence remains the ultimate arbiter of truth, especially for nuanced or high-stakes content.
Manual expert review
In critical domains like medicine or law, there is no substitute for a human expert reviewing the AI’s outputs. This process is slow but essential for verifying complex information where errors can have severe consequences.
End-user feedback
Incorporate a simple feedback mechanism (e.g., a thumbs-up/thumbs-down button) in your application. This provides a constant stream of real-world data on where the model is succeeding or failing, helping you identify and prioritize hallucination patterns reported by actual users.
How Do You Move from Detecting to Mitigating Hallucinations?
Identifying hallucinations is the first step. The next step is to reduce them. The most effective strategy is grounding the model in verifiable facts.
The leading technique for this is Retrieval-Augmented Generation (RAG). Instead of relying solely on its internal knowledge, a RAG system first retrieves relevant, up-to-date information from an external knowledge base (like a company’s internal documents or a trusted online encyclopedia). This retrieved context is then provided to the LLM along with the user’s prompt, effectively forcing the model to base its answer on the provided facts.
Other key mitigation strategies include:
Fine-tuning. Training the model on high-quality, curated, and domain-specific data.
Prompt engineering. Crafting clear, specific, and unambiguous prompts that constrain the model’s output and reduce its tendency to invent.
By combining a multi-tiered testing strategy with robust mitigation techniques like RAG, we can build AI systems that are not only powerful but also reliable and trustworthy.
How to Achieve Cross-Functional Integration
Generative AI hallucination testing cannot exist in isolation within QA teams. Effective detection and prevention require collaboration across engineering, product, domain experts, and customer-facing teams. Each group brings unique perspectives that enhance the overall effectiveness of testing.
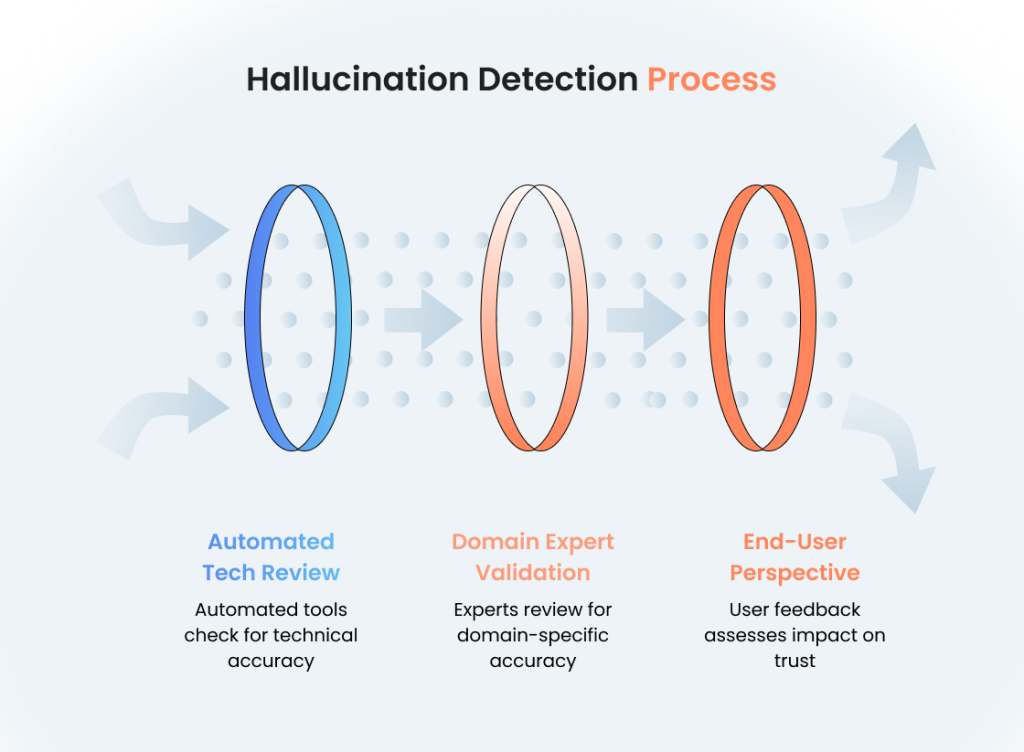
The three-layer review system
Multi-layered review processes catch different types of hallucinations by leveraging diverse expertise and perspectives. This redundancy is not inefficiency — it’s essential risk management.
Focus on technical accuracy and system consistency
Tools: Unit tests, integration tests, automated fact-checkers
Layer 2: Domain expert validation
Subject matter experts review outputs for domain-specific accuracy
Identify subtle hallucinations that automated systems miss
Frequency: Sample review of 5-10% of outputs weekly
Layer 3: End-user perspective
UX researchers and customer success teams evaluate impact
Focus on how hallucinations affect user trust and task completion
Method: User studies, feedback analysis, support ticket review
Building Domain Expert Networks
Access to domain expertise is crucial for identifying subtle hallucinations that may appear correct to non-specialists. Creating structured ways to engage these experts ensures their knowledge is effectively utilized without overwhelming them.
Expert panels. Establish rotating groups of 3-5 domain experts who review AI outputs monthly
Micro-consultations. Create a system where developers can quickly get 15-minute expert reviews for edge cases
Expert-in-residence programs. Rotate domain experts through QA teams for 1-2 week intensive collaboration periods
How Should QA Teams Adapt for AI Hallucinations In RAGs and LLMs?
While human judgment remains irreplaceable for detecting subtle hallucinations in generative AI applications, automation amplifies testing capacity and ensures consistent coverage. The key is finding the right balance between automated and manual testing approaches.
Building internal testing tools
Generic testing tools often miss domain-specific hallucination patterns. Investing in custom tooling tailored to your specific use cases and risk profiles yields better detection rates and faster feedback loops.
Hallucination dashboard. Real-time visualization of hallucination rates across different models and features
Prompt mutation engine. Automatically generates prompt variations to test response consistence
Regression test suite. Ensures fixes for past hallucinations don’t regress
Testing Data management
High-quality testing depends on high-quality test data. Managing this data as a strategic asset requires the same rigor applied to production data management.
Golden dataset curation. Maintain a constantly evolving set of verified correct responses
Adversarial example library. Collect prompts known to trigger hallucinations for regression testing
Version control for test data. Track how your testing datasets evolve over time
Metrics for testing RAG and generative AI models
What gets measured gets managed. Carefully chosen metrics can drive positive testing behaviors while poorly chosen ones can create perverse incentives that actually increase hallucination risk.
Leading indicators
These forward-looking metrics help predict future hallucination problems before they impact users. They focus on process health rather than just outcomes.
Testing coverage. Percentage of AI features with dedicated hallucination tests.
Detection latency. Time from hallucination occurrence to detection.
Expert review participation. Number of domain experts actively engaged in review processes.
Lagging indicators
These metrics measure actual impact and provide the ultimate scorecard for your hallucination prevention efforts. While they can’t prevent problems, they validate whether your testing culture is effective.
Production Hallucination Rate: Actual hallucinations reaching users
User Trust Scores: Survey data on user confidence in AI outputs
Support Ticket Categories: Percentage of support issues related to AI inaccuracies
Team health metrics
The sustainability of your testing culture depends on team wellbeing. These metrics help identify when testing burden becomes unsustainable or when teams need additional support.
Testing debt. Backlog of untested AI features or scenarios.
Knowledge sharing index. Frequency of hallucination-related knowledge transfer activities.
Tool adoption rate. Percentage of team using hallucination testing tools.
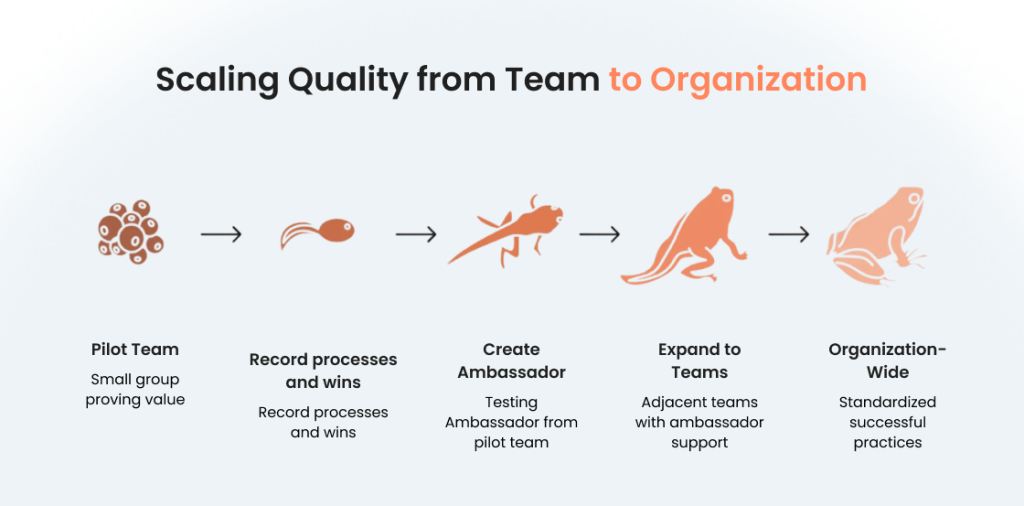
How to Mitigate AI Hallucinations Culture at Scale?
Moving from individual team success to organization-wide excellence requires deliberate planning and patience. Cultural change happens through demonstration, not declaration.
From team to organization
Successful scaling follows a predictable pattern: prove value with a small group, document successes, and gradually expand while maintaining quality. Rushing this process often results in superficial adoption that crumbles under pressure.
Center of Excellence model
Establish a dedicated Hallucination Testing CoE;
2-3 full-time experts who support all teams;
Responsible for tool development, training, and best practices;
Quarterly reviews with leadership on hallucination trends;
External collaboration.
No organization can solve the hallucination challenge alone. Building connections with peers, academics, and industry groups accelerates learning and prevents costly mistakes.
Industry partnerships
Join or create industry-specific hallucination testing groups;
Share non-competitive findings to advance the field;
Collaborate on open-source testing tools.
Academic connections
Partner with universities researching AI reliability;
Sponsor research into hallucination detection methods;
Recruit interns focused on AI testing.
Sustaining Momentum
Initial enthusiasm for hallucination testing often wanes as it becomes routine. Maintaining energy and engagement requires conscious effort to keep the work fresh, meaningful, and manageable.
Avoiding testing fatigue
Testing fatigue leads to checkbox compliance rather than genuine quality improvement. Combat this through variety, recognition, and continuous innovation in testing approaches.
Rotate focus areas. Don’t try to test everything all the time—use sprint-based focus areas
Celebrate small wins. Recognize incremental improvements in hallucination rates
Automate the mundane. Continuously move routine checks to automation
Innovation time. Allocate 20% of testing time for experimenting with new approaches
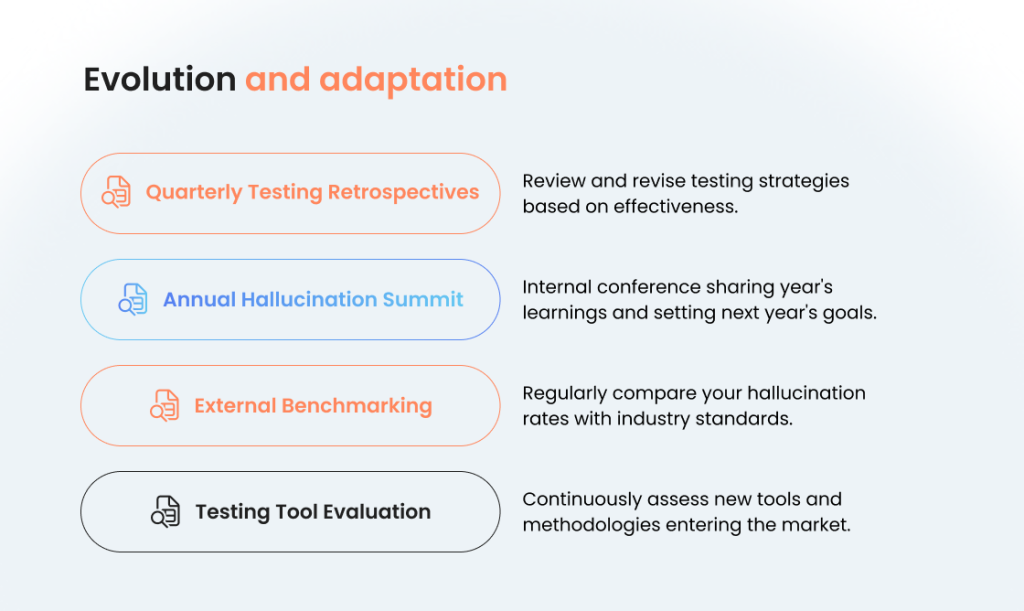
Evolution and adaptation
The only constant in AI development is change. Your testing culture must be designed for continuous evolution, incorporating new techniques, tools, and insights as they emerge.
The path forward
Building a sustainable testing culture for AI hallucinations isn’t a destination—it’s an ongoing journey. Success comes from treating hallucination testing not as a checkbox activity but as a core competency that differentiates responsible AI deployment from rushed implementation.
The organizations that thrive in the AI era will be those that build testing cultures robust enough to catch hallucinations before users do. They should also be flexible enough to adapt to new types of errors, and sustainable enough to maintain vigilance even as AI becomes routine. This culture doesn’t emerge overnight, but with deliberate effort, clear processes, and organizational commitment, it becomes the foundation for trustworthy AI systems that users can rely on.
Can’t tell if your AI is inventing or recalling facts?
We build automated groundedness checks and RAG systems to ensure your AI’s answers are based on verifiable data.
Hallucinations aren’t just bugs. You can’t patch them with a simple code fix. They’re a core behavior of LLMs, and treating them like traditional software defects will get you nowhere. This isn’t just another QA task; it’s a new discipline focused on building and maintaining trust.
We’ve covered the technical playbook — the metrics, the tiered testing strategies, and the power of RAG to ground models in reality. But the tools are only half the battle.
The real work is building an organization that prioritizes factual accuracy.
It’s a system, not a single tool. An effective strategy combines automated checks for scale, adversarial probes for weak spots, and essential human oversight for nuance. One without the others leaves you exposed.
Measure what actually matters. Forget vanity metrics. Focus on groundedness scores and concrete hallucination rates to understand your real-world risk. If you can’t measure it, you can’t manage it.
Words by
Oleksandr Drozdyuk, ML Lead, Gen AI Testing Expert
“Culture is your ultimate defense. Based on our work with enterprise clients and prevailing industry best practices, we recommend that teams allocate 30-40% of AI development project time specifically for testing, validation, and hallucination mitigation. This isn’t overhead — it’s a core component of building trustworthy systems.”
Ultimately, managing AI hallucinations is about risk management. You can’t eliminate them completely, but you can build the systems and processes to detect, measure, and contain them effectively.
Frequently Asked Questions (FAQ)
Can AI hallucinations be completely eliminated?
No, completely eliminating hallucinations is not currently possible due to the probabilistic nature of LLMs. The goal is to manage and reduce them to an acceptable level for a given application through robust testing and mitigation strategies like RAG.
What is the single most effective technique to prevent hallucinations?
Retrieval-Augmented Generation (RAG) is widely considered the most effective technique. By grounding the AI’s response in specific, verified external documents, it forces the model to rely on provided facts rather than its internal, and potentially flawed, knowledge.
How is testing for AI hallucinations different from traditional software QA?
Traditional QA tests for deterministic bugs (e.g., a button not working). Hallucination testing addresses non-deterministic, probabilistic errors. It requires a different mindset focused on evaluating factual accuracy and logical consistency rather than predictable code failures.
Share:
Jump to section
Hand over your project to the pros.
Let’s talk about how we can give your project the push it needs to succeed!
A commercial writer with 13+ years of experience. Focuses on content for IT, IoT, robotics, AI and neuroscience-related companies. Open for various tech-savvy writing challenges. Speaks four languages, joins running races, plays tennis, reads sci-fi novels.
An experienced QA engineer with deep knowledge and broad technical background in the financial and banking sector. Igor started as a software tester, but his professionalism, dedication to personal growth, and great people skills quickly led him to become one of the best QA Team Leads in the company. In his free time, Igor enjoys reading psychological books, swimming, and ballroom dancing.





 Can AI hallucinations be completely eliminated?
Can AI hallucinations be completely eliminated?

