Testing Artificial Intelligence systems should be based on a fundamentally different approach than old-school software testing.
Traditional software follows clear rules and produces predictable outputs. AI solutions learn from data and make probabilistic decisions.
The consequences of inadequate AI testing result in biased hiring recommendations, inaccurate healthcare information, or misclassified objects in safety-critical situations.
What makes AI testing particularly challenging is its complexity. Traditional software either works correctly or fails obviously. AI systems can appear to function well while hiding subtle problems that only emerge in specific situations or with certain data inputs.
The EU AI Act introduces clear requirements and significant penalties for non-compliant systems. Organizations need to implement robust testing frameworks not just for technical performance, but also for fairness, transparency, and privacy.
The cost of not properly testing AI systems — in terms of regulatory penalties, reputational damage, and potential harm — far outweighs the investment in proper testing procedures.
This article is all about them.
Key takeaways
#1. AI fails differently. Traditional software crashes. AI gives wrong answers that look right.
#2. Data testing comes first. Bad data guarantees bad models. Quality checks prevent 30-50% of AI failures.
#3. Three-layer testing approach. Test the foundation, the model itself, and real business impact.
#4. Non-deterministic challenges. The same inputs can yield different outputs. Use statistical testing instead of exact matches.
#5. Ethical testing isn’t optional. EU AI Act penalties are severe. Bias testing is now a legal requirement.
#6. Specialized metrics matter. Use AI-specific metrics: AUC-ROC, precision/recall, RMSE, BLEU, perplexity.
#7. Generative AI needs unique approaches. LLMs require specialized testing for hallucinations and prompt sensitivity.
#8. Continuous monitoring is essential. Models degrade as real-world data shifts. Monitor constantly.
#9. Documentation as defense. Document limitations and test results to protect against compliance issues.
#10. Cost-benefit reality. Thorough testing costs more upfront but delivers 4-5x ROI through reduced failures.
Need help assessing your AI testing readiness?
Our experts can evaluate your current AI testing practices and identify critical gaps in just 2 weeks.

Why Test AI Applications at All?
Unlike traditional software, AI and ML systems aren’t programmed explicitly — instead, they learn from data. This makes them powerful but introduces peculiar risks and uncertainties.
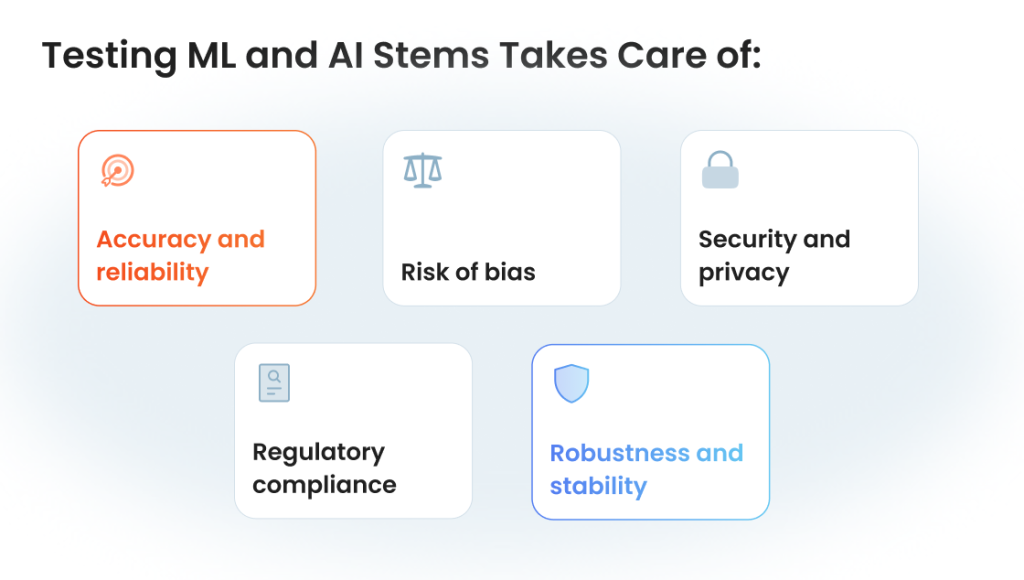
Accuracy and reliability. Even small errors in AI predictions can significantly affect business operations and user trust. Continuous testing of AI applications identifies inconsistencies and improves prediction reliability.
Risk of bias. AI models learn from data that often reflects existing biases. Testing helps your models to remain fair and compliant with ethical standards and regulations.
Security and privacy. AI-driven systems frequently handle sensitive data. Security testing reveals vulnerabilities and protects data integrity, confidentiality, and user privacy.
Regulatory compliance. Increasingly strict regulations around AI (e.g., EU AI Act, GDPR, HIPAA) require robust testing documentation. Failing compliance = heavy penalties and brand damage.
Robustness and stability. Users expect AI applications to perform consistently under real-world conditions. You need to make sure your model maintains stable performance despite unexpected inputs or scenarios.
If you don’t, you risk unreliable outputs, reinforce harmful biases, violate compliance standards, or expose sensitive information.
Current Challenges Associated with Testing AI Software
We will not talk much here about standard problems and tech issues every software has. You know those already. Let’s focus on challenges of testing machine learning models and Gen AI tools that are caused by their inherent complexity and learning-based nature.
Technical challenges
Non-deterministic outcomes. AI models can produce different results even with identical inputs. It complicates validation and verification. Unpredictability demands extensive testing and monitoring scenarios for consistent performance.
Complexity of training data and model behavior. Large datasets and sophisticated model architectures make finding the exact source of errors difficult. You need advanced testing solutions to analyze data quality, relevance, and coverage.
Versioning and reproducibility. AI models constantly evolve through retraining and updates. Managing model versions and reproducing past behaviors to validate improvements or identify regressions is technically demanding.
Adversarial vulnerability. AI products, especially deep learning ones, can be susceptible to adversarial attacks — inputs intentionally crafted to deceive models. Planned testing must consider methods that detect and defend against such vulnerabilities.
Resource intensity. AI and ML model testing often requires significant computational power and specialized infrastructure, making testing resource-intensive and potentially costly.
| Technical challenge | Description | Suggested mitigation approach |
| Non-deterministic outcomes | Unpredictable results from the same inputs | Implement comprehensive, repeated validation tests |
| Complexity of data/model behaviors | Difficulty in isolating errors due to complexity | Employ specialized diagnostic tools and analytics |
| Versioning and reproducibility | Difficulty tracking changes and ensuring repeatability | Use robust version control and tracking systems |
| Adversarial vulnerability | Susceptibility to intentional deceptive inputs | Conduct adversarial testing regularly |
| Resource intensity | High computational and infrastructure demands | Optimize testing environments and leverage cloud resources |
Operational challenges
In our experience, scale, complexity, and continuous evolution of machine learning workflows affect operational aspects of testing AI.
Integration into CI/CD pipelines. Traditional CI/CD processes often don’t effectively accommodate ML workflows. AI testing requires frequent model retraining, data updates, and performance validation, requiring specialized integrations.
Dataset management. AI model testing demands handling large, diverse datasets that must be continuously refreshed and validated. Efficient storage, access, and dataset versioning is critical but challenging to manage at scale.
Scalability and performance constraints. AI tests require vast computational resources and can quickly strain infrastructure.
| Operational challenge | Impact | Practical solutions |
| CI/CD Integration | Difficulties in automating frequent ML processes | Custom CI/CD pipeline extensions for ML workflows |
| Large Dataset Management | Complex, resource-heavy data operations | Implement robust data versioning tools and practices |
| Scalability & Performance | Infrastructure strain and delayed testing cycles | Use scalable cloud infrastructure and automated resource management |
Ethical and regulatory challenges in testing AI
Very soon, when speaking about how to test AI models, we will start not with performance or even security but with ethics and compliance of ML testing. The traditional software testing approach is no longer viable for planning QA for AI-based applications.
It’s fair. Regulators know that most of the companies have experienced QA teams to cover technical testing of AI systems and machine learning applications. But resilience of AI in terms of personal data vulnerability, bias risks and general applied ethics field requires both extra attention and extra regulations.
Bias detection and fairness
Bias isn’t theoretical — it has real-world implications. Consider Amazon’s recruitment AI, scrapped after it systematically disadvantaged female candidates due to historical hiring data biases. Bias audits and fairness testing methodologies, like IBM’s AI Fairness 360 toolkit, allow early detection and correction of biases.
Transparency and explainability
Healthcare AI recommending treatments without explaining the rationale already leaves doctors hesitant and confused, leading to slow adoption. Robust explainability testing, employing tools like SHAP, LIME, or Explainable Boosting Machines (EBM), ensures AI decisions are transparent, justified, and trustworthy.
Data privacy and protection
In 2021, an AI-driven banking app mistakenly exposed customer transaction details, resulting in a multi-million euro GDPR fine and damaged trust. Effective AI testing must enforce rigorous data anonymization practices and rely on secure testing environments.
Compliance with the EU AI Act
The EU AI Act introduces clear risk-based classifications (unacceptable, high, limited, minimal) with defined testing and documentation standards. Organizations should adopt comprehensive AI lifecycle documentation, maintain robust audit trails, and implement continuous compliance checks.
Companies that neglect rigorous AI testing and transparent documentation face substantial financial penalties and possible product bans within EU markets.
| Ethical & Regulatory Challenge | Real-world Example | Mitigation Actions |
| Bias and Fairness | Amazon’s recruitment AI bias controversy | Regular bias audits, fairness metrics, structured evaluations |
| Transparency & Explainability | Ambiguous healthcare AI recommendations | Explainability frameworks (SHAP, LIME, EBM), clear model reporting |
| Data Privacy & Protection | Financial AI app data breach incident | Privacy-preserving techniques, secure environments, regular compliance audits |
| Regulatory Compliance (AI Act) | Potential fines and bans due to compliance failures | Structured documentation, clear risk management processes, ongoing compliance training |
| Ethical Decision-making | Autonomous vehicles causing accidents | Ethical impact assessments, scenario-based ethical testing |
| Accountability & Liability | AI medical diagnostics errors | Clear responsibility definitions, liability frameworks |
Dealing with ethical and regulatory challenges proactively mitigates risk and reinforces user trust, brand reliability. It also ensures your AI-driven solutions sustainably align with societal and regulatory expectations. “Testing for ethics” will be a new type of testing used for AI algorithms alongside compliance, security and usability testing.
Quick questionnaire for ethical AI testing
Use these simple questions to start evaluating your AI system’s ethical and regulatory readiness:

AI App Testing: Types, Tools, Differences
Testing AI applications requires a more comprehensive approach than traditional software testing. The unique characteristics of machine learning models — their probabilistic nature, reliance on data quality, and potential for unexpected behaviors — demand specialized testing methods. Here’s a breakdown of essential testing types for AI systems:
Data testing
AI performance directly depends on data quality. Poor or biased training data inevitably leads to flawed models, making data testing a critical first step.
| Key testing areas | ||
| Data quality validation | Distribution analysis | Bias detection |
| Check for missing values, outliers, duplicates, and inconsistencies. | Ensure training data accurately represents real-world scenarios. | Identify and mitigate unwanted patterns in training data that could create unfair model outputs. |
| Tools | ||
| Great Expectations, Deequ, WhyLogs | ||
Model validation testing
This testing validates that the model works as intended across various scenarios, not just on cherry-picked examples.
| Key testing areas | ||
| Performance validation | Cross-validation | Generalization testing |
| Test model accuracy, precision, and recall across different data subsets. | Ensure the model performs consistently across different data splits. | Verify that the model works well with previously unseen data. |
| Tools | ||
| Scikit-learn, MLflow, TensorBoard | ||
Security testing
AI systems introduce unique security concerns beyond traditional applications, including data poisoning, model stealing, and adversarial attacks.
| Key testing areas | ||
| Adversarial testing | Model inversion attacks | Access control |
| Test model robustness against deliberately manipulated inputs | Check if sensitive training data can be extracted from the model | Test permission systems for model usage and data access |
| Tools | ||
| ART (Adversarial Robustness Toolbox), Cleverhans, OWASP ZAP | ||
Functional testing
Functional testing focuses on whether the AI system meets its specified requirements and performs its intended tasks correctly.
| Key testing areas | ||
| API integration testing | Business logic validation | End-to-end testing |
| Test model endpoints and data pipelines | Ensure the model’s decisions align with business rules | Verify all components work together correctly |
| Tools | ||
| Pytest, Postman, Selenium | ||
Load and performance testing
AI systems often have different performance characteristics than traditional software, with unique resource needs and potential bottlenecks.
| Key testing areas | ||
| Inference latency | Throughput testing | Resource utilization |
| Measure response time under various conditions | Measure response time under various conditions | Monitor CPU, GPU, memory usage during model operation |
| Tools | ||
| Locust, k6, TensorRT | ||
Bias and fairness testing
Ethical considerations are crucial for AI systems to ensure they treat all users fairly and don’t perpetuate or amplify existing biases.
| Key testing areas | ||
| Demographic parity | Equal opportunity | Disparate impact analysis |
| Test if predictions are independent of protected attributes | Ensure similar true positive rates across different groups | Check for unintended consequences across demographic groups |
| Tools | ||
| Fairlearn, AI Fairness 360, What-If Tool | ||
Generative AI-specific testing
Generative AI systems like chatbots and image generators require specialized testing approaches that evaluate the quality and appropriateness of outputs.
| Key testing areas | |||
| Output quality evaluation | Hallucination detection | Prompt robustness | Toxicity screening |
| Assess coherence, relevance, creativity of generated content | Identify when models generate factually incorrect information | Test how model outputs vary with different prompts and instructions | Ensure generated content meets ethical and safety standards |
| Tools | |||
| LangChain, ROUGE/BLEU, PromptFoo, TruLens | |||
Key differences from traditional testing
AI testing differs from conventional software testing in several important ways:
| Aspect | Traditional software testing | AI/ML testing |
| Determinism | Expects consistent results for the same inputs | Must account for probabilistic outputs and acceptable ranges |
| Debugging | Clear relationship between inputs and outputs | Complex model internals create “black box” challenges |
| Test data | Can often use synthetic data | Requires representative, diverse real-world data |
| Evaluation | Binary pass/fail metrics common | Uses statistical performance measures (accuracy, F1 score, etc.) |
| Regression | Changes should not affect existing functionality | Model improvements in one area may cause degradation in others |
Don’t let AI quality issues damage your reputation or bottom line.
Our end-to-end QA services cover the entire AI development lifecycle

Automated Testing Frameworks for Generative AI
Unlike deterministic systems that produce consistent outputs for given inputs, generative AI creates novel content — text, images, code, audio — that can vary significantly even with identical prompts. This fundamental difference requires specialized approaches to testing generative AI applications.
Specific testing challenges of generative AI
Output variability. The same prompt can produce different outputs each time, making traditional exact-match assertions ineffective.
Hallucinations. Models can generate plausible but factually incorrect information that’s difficult to automatically detect without reference data.
Qualitative evaluation. Many aspects of generative output quality (creativity, coherence, relevance) are subjective and hard to quantify.
Prompt sensitivity. Minor changes in prompts can drastically alter outputs, requiring robust testing across prompt variations.
Regression detection. Model updates may fix certain issues while introducing others, making regression testing complex.
Key testing frameworks and tools
LangChain testing framework
Provides tools specifically designed for testing LLM applications.
from langchain.evaluation import StringEvaluator from langchain.smith import RunEvalConfig # Define evaluation criteria evaluation = StringEvaluator(criteria=”correctness”) # Configure test runs eval_config = RunEvalConfig( evaluators=[evaluation], custom_evaluators=[check_factual_accuracy] )
Strengths
- Integrates with popular LLM platforms
- Supports custom evaluation functions
- Enables testing of entire chains and agents
Limitations
- Primarily focused on text generation
- Requires programming knowledge to set up
Promptfoo
Enables systematic testing of prompts across different models.
prompts: – file: prompts/customer-service.txt – file: prompts/product-description.txt models: – gpt-4 – claude-3 tests: – description: “Check for appropriate tone” assert: – type: “contains” value: “thank you” – type: “not-contains” value: “sorry for the inconvenience”
Strengths
- Visual interface for test management
- Supports multiple LLMs for comparison
- Enables version control of prompts
Limitations
- Limited support for non-text outputs
- Mainly focused on prompt engineering
TruLens
TruLens focuses on evaluation and monitoring of LLM applications.
from trulens.core import TruSession from trulens.evaluators import Relevance session = TruSession() relevance = Relevance() with session.record(app, evaluators=[relevance]) as recording: response = app.generate(“Explain quantum computing”) # Get evaluation results results = recording.evaluate()
Strengths
- Real-time monitoring capabilities
- Multiple built-in evaluators (relevance, groundedness, etc.)
- Works with major LLM frameworks
Limitations
- Steeper learning curve
- More focused on evaluation than comprehensive testing
MLflow with LLM Tracking
MLflow has expanded to support LLM testing.
import mlflow from mlflow.llm import log_predictions, evaluate_model # Log model predictions log_predictions( model_name=”my-llm”, inputs=test_prompts, outputs=model_responses ) # Evaluate model results = evaluate_model( model_name=”my-llm”, evaluators=[“factual_consistency”, “toxicity”] )
Strengths
- Integrates with existing ML workflows
- Comprehensive experiment tracking
- Supports model versioning
Limitations
- Requires additional setup for generative AI metrics
- Lacks specialized generative AI testing features
Deepchecks
Deepchecks provides data validation and model evaluation.
from deepchecks.nlp import Suite from deepchecks.nlp.checks import TextDuplicates, OutOfVocabulary suite = Suite( “Generative Text Validation”, checks=[ TextDuplicates(), OutOfVocabulary() ] ) results = suite.run(train_dataset, test_dataset, model)
Strengths:
- Strong focus on data quality
- Detects drift and outliers
- Visual reporting
Limitations:
- Less focused on creative aspects of generation
- Primarily designed for NLP models
Testing strategies for different generative AI outputs
Text Generation Testing
Assertion-based approaches
- Content inclusion. Check that outputs contain key required information
- Content exclusion. Verify outputs avoid prohibited content or misinformation
- Semantic similarity. Use embeddings to assess closeness to reference answers
Example implementation
def test_response_contains_required_info(prompt, response): required_points = [“pricing options”, “delivery timeframe”] return all(point in response.lower() for point in required_points)
Image generation testing
Automated visual quality checks
- CLIP-based evaluation. Measure text-image alignment
- FID and IS scores. Assess perceptual quality and diversity
- Style and content consistency. Verify adherence to input specifications
Code Generation Testing
Functional validation
- Compilation testing. Verify generated code compiles without errors
- Unit test execution. Run generated code against test cases
- Static analysis. Check code quality metrics (complexity, maintainability)
Example approach
def test_generated_code(prompt, code_response): # Write code to temp file with open(‘temp_code.py’, ‘w’) as f: f.write(code_response) # Execute code with test inputs result = subprocess.run([‘python’, ‘temp_code.py’], input=’test input’, capture_output=True) # Check execution succeeded return result.returncode == 0
Automated testing workflow integration
To effectively integrate generative AI testing into development workflows.
- Define test suites. Create collections of prompts and expected response characteristics.
- Implement CI/CD pipelines. Automate testing on model updates or prompt changes
# Example GitHub Actions workflow steps: – uses: actions/checkout@v3 – name: Run LLM tests run: python -m pytest tests/llm_tests.py – name: Evaluate model responses run: python evaluate_model_outputs.py - Set up monitoring. Track performance metrics in production to detect degradation
- Response quality scores
- User feedback metrics
- Factual accuracy rates
- Establish feedback loops. Continuously improve test coverage based on production issues
Human-in-the-loop testing
Some aspects of generative AI require human evaluation:
Human evaluation processes
- Controlled A/B testing. Compare outputs of different models or prompts
- Quality rating scales. Define consistent criteria for human evaluators
- Diverse evaluator panels, Ensure different perspectives are represented
Automation opportunities
- Automated filtering. Use models to pre-filter outputs for human review
- Targeted evaluation. Direct human attention to high-risk or uncertain cases
- Learning from feedback. Use human evaluations to train automated classifiers
An NLP development team reduced manual review time by 65% by implementing an automated classifier that flagged only the 12% of outputs that fell below confidence thresholds for human review.
Test data management
Effective generative AI testing requires careful test data handling:
Representative prompt collections. Create diverse prompts covering various use cases, edge cases, and potential vulnerabilities
Golden dataset curation. Maintain reference outputs for critical prompts to detect regressions
Adversarial examples. Include prompts designed to challenge model limitations or trigger problematic behaviors
Version control. Track changes to test prompts and expected outputs alongside model versions
Measuring test coverage
Traditional code coverage metrics don’t apply well to generative AI. Instead, consider:
- Prompt space coverage. How well do test prompts cover the expected input space?
- Edge case coverage. Are boundary conditions and rare scenarios tested?
- Behavioral coverage. Do tests verify all expected model capabilities?
- Vulnerability coverage. Are known failure modes and risks tested?
The future of generative AI testing
As generative AI continues to evolve, testing frameworks are advancing to address emerging challenges:
- Multi-modal testing. Integrated testing across text, image, audio, and video outputs
- Self-testing models. Models that can evaluate and verify their own outputs
- Explainability tools. Frameworks that help understand why models generate specific outputs
- Standardized benchmarks. Industry-wide standards for generative AI quality and safety
By adopting these automated testing frameworks and strategies, development teams can deliver more reliable, accurate, and trustworthy generative AI applications that meet business requirements while managing the unique risks these systems present.
Integrate AI testing directly into your development workflow.
Our experts build business-focused automated testing pipelines.
ML Software Testing Best Practices
Machine learning systems demand a fundamentally different testing mindset than traditional software. Where conventional applications follow deterministic rules, ML models operate on probabilistic patterns, creating unique quality assurance challenges.
Three layers of ML testing maturity
ML models are designed differently from anything we have seen before. That is why it requires unique testing approach — not just rigorous testing, but Quality Engineering that takes into account how the model is trained and which decisions based on that data will be made.
Think of ML testing as a pyramid with three distinct layers, each building upon the last to create increasingly robust systems.
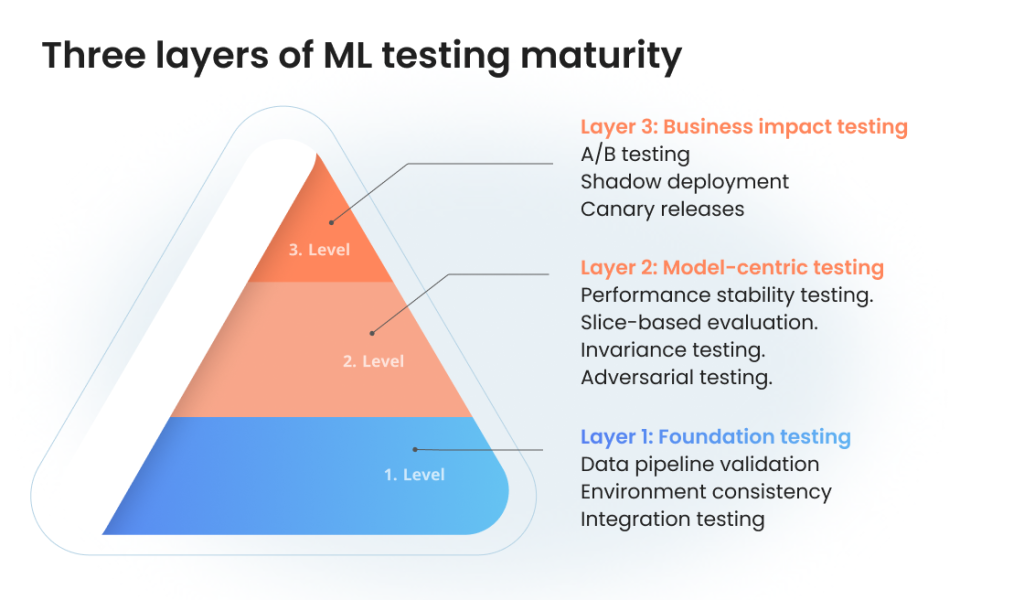
Layer 1: Foundation testing
At the base of our pyramid sits the fundamental infrastructure that supports ML operations. This layer focuses on testing the technical components that enable model operations.
Testing at this level ensures your data pipelines, training processes, and deployment mechanisms function correctly.
- Data pipeline validation confirms data is flowing correctly from sources to training environments.
- Environment consistency checks ensure your development, testing, and production environments process data identically.
- Integration testing — API endpoints, data serialization/deserialization, and error handling — verifies that your model correctly interfaces with upstream and downstream systems.
Layer 2: Model-centric testing
The middle layer focuses on the ML model itself — its accuracy, behavior, and performance characteristics.
The central question at this level: “Does the model perform as expected across various scenarios?”.
- Performance stability testing. Train your model multiple times with identical hyperparameters. Significant variations in results may indicate instability in your training process.
- Slice-based evaluation. Test model performance across important data subgroups.
- Invariance testing. Verify that model predictions remain stable when irrelevant features change.
For example, an image recognition model shouldn’t change its classification of a car because the background color changes.
- Adversarial testing. Intentionally provide challenging inputs designed to cause model failures.
Layer 3: Business impact testing
The top layer of our pyramid connects model performance to actual business outcomes. Testing at this level ensures the ML system delivers real-world value.
This is often overlooked yet crucial—a technically “accurate” model that doesn’t improve business metrics is ultimately a failed project.
- A/B testing new models against current production systems with real user traffic provides the most reliable measure of business impact. Set clear success metrics tied to business goals.
- Shadow deployment runs new models alongside existing systems, logging what the new model would have done without actually affecting users.
- Canary releases gradually roll out new models to increasing percentages of users, monitoring for issues before full deployment.
Testing lifecycle: From development to monitoring
Effective ML testing isn’t a one-time activity but a continuous process throughout the model lifecycle.
Pre-development: Setting the foundation
Before writing a single line of code, establish clear, measurable objectives for your ML system. Document both functional requirements (what the model should do) and performance requirements (how well it should do it).
Define acceptance criteria that bridge technical metrics and business outcomes. For a recommendation system, this might include:
- Technical criteria: 85%+ precision@10, latency under 100ms
- Business criteria: 5%+ increase in click-through rate, 3%+ increase in revenue per session
Development: Building with quality
During active development, implement automated testing at multiple levels:
Unit Tests → Component Tests → Integration Tests → System Tests
- Unit tests verify individual functions and transformations.
- Component tests validate distinct modules like data pipelines or training loops.
- Integration tests check interactions between components.
- System tests evaluate the end-to-end ML system.
Deployment: Validating in production
When transitioning to production, implement a staged deployment process:
- Pre-flight checks: Verify model artifacts, configurations, and dependencies before deployment
- Controlled rollout: Start with a small percentage of traffic, gradually increasing as confidence builds
- Automated rollback: Establish thresholds for performance degradation that trigger automatic reversion to previous model versions
Post-Deployment: Continuous monitoring
Once in production, ML systems require continuous monitoring to detect issues:
- Input monitoring tracks the distribution of incoming data, alerting when drift exceeds thresholds.
- Output monitoring watches model predictions for unexpected patterns or shifts.
- Performance monitoring tracks accuracy, latency, and resource usage over time.
A manufacturing company implemented comprehensive monitoring for their defect detection system. When a supplier changed their materials slightly, input monitoring detected the shift before quality problems occurred, allowing proactive model adjustment.
Cross-cutting testing concerns
Several testing practices apply across all stages of ML development.
Documentation as a testing tool
Treat documentation as an executable specification. Clear documentation of model inputs, outputs, constraints, and assumptions serves as both a guide for developers and a basis for test case generation.
Document known limitations explicitly. No model is perfect, and acknowledging edge cases where your model underperforms creates transparency and helps prevent misuse.
Data quality gates
Implement automated data quality checks that must pass before data enters your training pipelines:
# Example data quality check def validate_dataset(df): # Check for missing values missing = df.isnull().sum().sum() # Check for distribution anomalies numeric_columns = df.select_dtypes(include=[‘number’]).columns z_scores = df[numeric_columns].apply(stats.zscore) outliers = (z_scores > 3).sum().sum() # Check for class imbalance if ‘target’ in df.columns: class_counts = df[‘target’].value_counts() balance_ratio = class_counts.min() / class_counts.max() else: balance_ratio = 1.0 return { ‘missing_values’: missing < 100, # Threshold ‘outliers’: outliers < 500, # Threshold ‘class_balance’: balance_ratio > 0.2 # Threshold }
These gates prevent problematic data from corrupting your models and establish clear quality standards for data providers.
Reproducibility requirements
Make reproducibility a core testing requirement. Every model training run should be fully reproducible from the same inputs and random seeds.
Store all artifacts necessary for reproduction:
- Training data (or references to immutable versions)
- Model hyperparameters
- Environment configurations
- Random seeds
- Feature transformation code
This allows proper debugging when issues arise and ensures consistent behavior from development to production.
Practical implementation roadmap
Implementing comprehensive ML testing doesn’t happen overnight. Follow this progressive approach to build testing maturity:
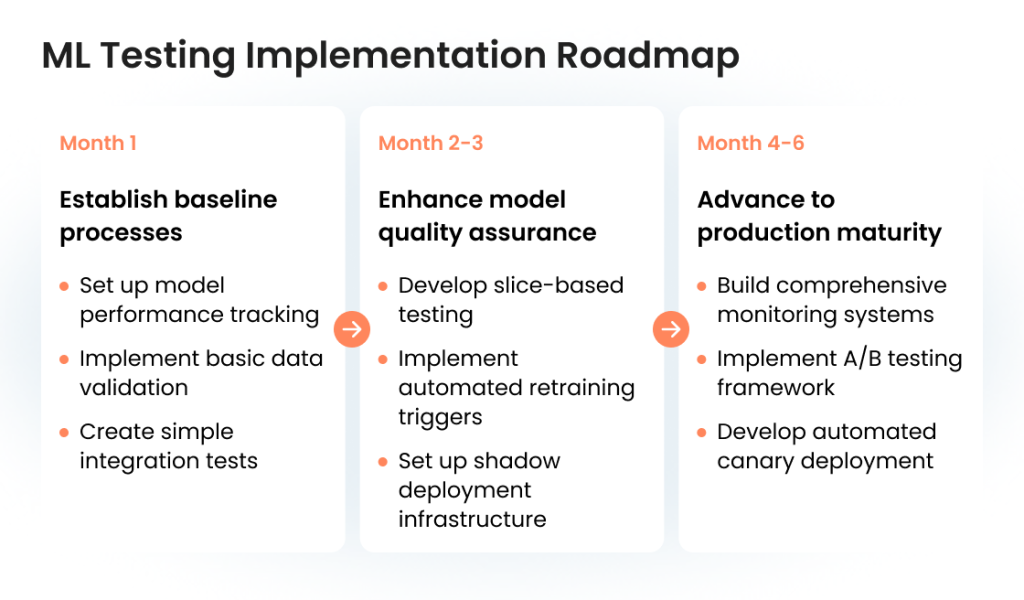
By gradually building your ML testing capabilities, you create a sustainable foundation for reliable AI applications that deliver consistent business value.
Every AI project has unique quality challenges.
Tell us about yours, and we’ll recommend the right testing approach.

Evaluation Metrics for ML Models
Selecting the right metrics to evaluate machine learning models is critical to ensure they meet business objectives. Different ML applications require different evaluation approaches, and understanding these metrics helps teams make informed decisions about model deployment and improvement.
Classification model metrics
Classification models predict discrete categories (e.g., spam detection, fraud identification, customer churn). Key metrics include:
Accuracy. The percentage of correct predictions.
Accuracy = (True Positives + True Negatives) / All Predictions
While intuitive, accuracy can be misleading for imbalanced datasets where one class dominates. A fraud detection model that always predicts “not fraud” might achieve 99% accuracy if only 1% of transactions are fraudulent — but would be useless in practice.
Precision. The percentage of positive predictions that were actually correct.
Precision = True Positives / (True Positives + False Positives)
High precision means few false positives. This is essential when false positives are costly or disruptive, such as in spam filtering where legitimate emails incorrectly marked as spam create serious business problems.
Recall (Sensitivity). The percentage of actual positives correctly identified.
Recall = True Positives / (True Positives + False Negatives)
High recall means few false negatives. This is crucial when missing a positive case is expensive or dangerous, such as in cancer detection or security threat identification.
F1 Score. The harmonic mean of precision and recall, providing a balance between the two.
F1 Score = 2 * (Precision * Recall) / (Precision + Recall)
F1 score helps when you need to balance precision and recall, particularly with imbalanced data.
AUC-ROC (Area Under the Receiver Operating Characteristic Curve). Measures the model’s ability to distinguish between classes across different threshold settings.
Values range from 0.5 (random guessing) to 1.0 (perfect classification). A model with AUC-ROC of 0.85 or higher typically indicates good discriminative ability.
Confusion matrix. A table showing predicted vs. actual outcomes, providing a complete picture of model performance:
| Predicted Positive | Predicted Negative | |
| Actual Positive | True Positive (TP) | False Negative (FN) |
| Actual Negative | False Positive (FP) | True Negative (TN) |
All classification metrics derive from these four fundamental values.
Regression model metrics
Regression models predict continuous values (e.g., price forecasting, demand prediction). Key metrics include:
Mean Absolute Error (MAE). The average of absolute differences between predicted and actual values.
MAE = (1/n) * Σ|actual – predicted|
MAE is intuitive and directly interpretable in the original units of the target variable, making it easy to explain to stakeholders.
Mean Squared Error (MSE). The average of squared differences between predicted and actual values.
MSE = (1/n) * Σ(actual – predicted)²
MSE penalizes larger errors more heavily than smaller ones, which is useful when large errors are particularly problematic.
Root Mean Squared Error (RMSE). The square root of MSE, bringing the metric back to the original units.
RMSE = √MSE
RMSE is widely used in forecasting and financial models where the magnitude of error can significantly impact business decisions.
R-squared (Coefficient of Determination). The proportion of variance in the dependent variable explained by the model.
R² = 1 – (Sum of Squared Residuals / Total Sum of Squares)
R² ranges from 0 to 1, with higher values indicating better fit. A value of 0.7 means the model explains 70% of the variance in the data.
NLP and text generation metrics
Natural language processing models require specialized metrics:
BLEU (Bilingual Evaluation Understudy): Measures the similarity between machine-generated text and reference text, commonly used for translation.
- Scores range from 0 to 1, with 1 being perfect match.
- A BLEU score above 0.3 indicates understandable text, above 0.5 indicates good quality.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): A set of metrics for evaluating automatic summarization.
- ROUGE-N measures n-gram overlap.
- ROUGE-L measures longest common subsequence.
Perplexity: Measures how well a language model predicts text.
- Lower perplexity indicates better prediction.
- Modern large language models aim for perplexity below 20 on standard benchmarks.
BERTScore: Computes similarity between generated and reference text using contextual embeddings.
- Captures semantic similarity better than exact match metrics.
- Correlates better with human judgment than traditional metrics.
Image and video generation metrics
For visual AI models, specialized metrics include:
FID (Fréchet Inception Distance): Measures similarity between generated and real images.
- Lower FID scores indicate more realistic images.
- State-of-the-art generative models typically achieve FID scores below 5.
SSIM (Structural Similarity Index): Measures perceived similarity between images.
- Ranges from -1 to 1, with 1 indicating perfect similarity.
- Captures structural information better than pixel-level comparisons.
PSNR (Peak Signal-to-Noise Ratio): Measures reconstruction quality in image compression.
- Higher values indicate better quality.
- Typically ranges from 20 to 40 dB for acceptable quality.
Fairness and bias metrics
Ethical AI requires evaluating model fairness across different demographic groups:
Demographic parity. Measures whether the positive prediction rate is the same across all protected groups.
|P(Ŷ=1|A=a) – P(Ŷ=1|A=b)| should be close to zero
Where A represents a protected attribute like gender or race.
Equal opportunity. Measures whether the true positive rate is the same across all protected groups.
|P(Ŷ=1|Y=1,A=a) – P(Ŷ=1|Y=1,A=b)| should be close to zero
Disparate impact. Ratio of the positive prediction rate for the unprivileged group to that of the privileged group.
P(Ŷ=1|A=unprivileged) / P(Ŷ=1|A=privileged)
The 80% rule in US law suggests this ratio should be at least 0.8 to avoid disparate impact.
Practical Implementation of ML Testing Metrics
When implementing evaluation metrics for ML models in production:
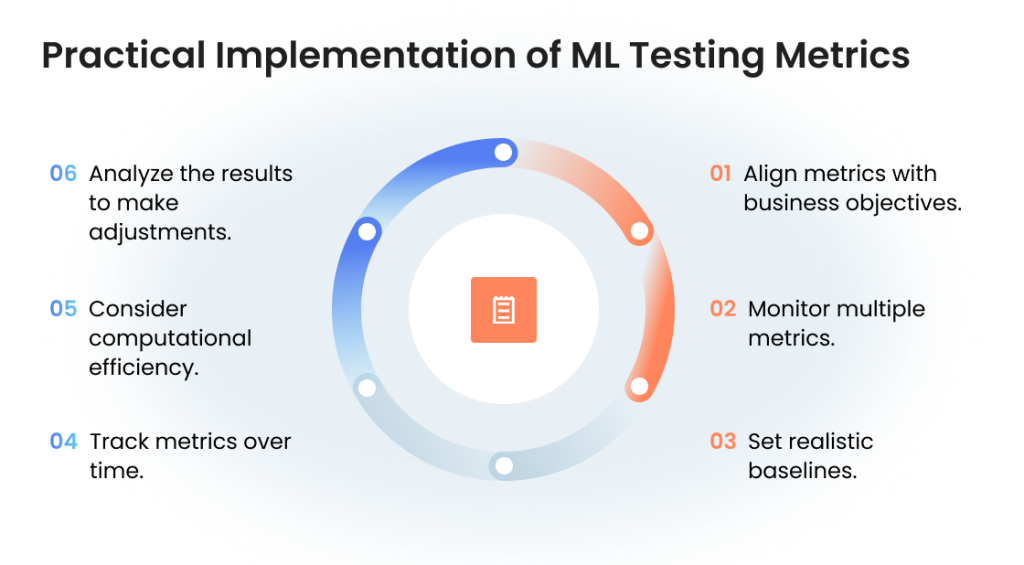
The right metrics differentiate academic exercises from business-driving AI applications. Teams testing machine learning models ensure that systems deliver measurable value by selecting metrics that reflect genuine business needs and stakeholder concerns.
Wrapping Up: Testing AI-Based and ML Solutions
The probabilistic nature of AI, its reliance on data quality, and its potential for unintended behaviors create testing challenges that standard QA approaches can’t address.
The cost of inadequate AI testing:
- Compromised accuracy that erodes user trust;
- Hidden biases that create legal and ethical problems;
- Security vulnerabilities unique to AI architectures;
- Compliance gaps that expose your business to regulatory penalties.
The organizations succeeding with AI aren’t necessarily those with the most advanced models, but those with the most reliable testing frameworks. They catch problems early, validate model performance across different scenarios, and monitor systems continuously in production.
The companies that invest in proper AI testing now will avoid the costly fixes, reputation damage, and regulatory penalties that come with AI failures.
Start with the basics:
- Establish clear performance requirements tied to business outcomes;
- Implement comprehensive data quality testing;
- Validate model performance across diverse scenarios;
- Monitor deployed models for drift and degradation;
- Build fairness and ethical considerations into every testing stage.
The best AI isn’t the smartest or the fastest — it’s the one that consistently delivers value without unexpected failures. And that is what your testing process should focus on.
With the right testing approach, you can build AI systems that your business and customers can genuinely trust.
Jump to section
Hand over your project to the pros.
Let’s talk about how we can give your project the push it needs to succeed!